

简要介绍
Yolov5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。Yolov5的网络结构主要由Backbone、Neck、Head构成,其中Backbone主要使用CSPdarknet+SPP结构,Neck使用PANet结构,Head使用yolov3 head。
Yolov5官方代码中,给出的目标检测网络中共有4个版本,分别是Yolov5s、Yolov5m、Yolov5x、Yolov5l四个模型,本文以Yolov5s为例在MLU270上进行移植、测试,其他类比。
准备工作
- Yolov5官方源码:https://github.com/ultralytics/yolov5/
- 官方docker:io/ultralytics/yolov5:v4.0 【https://hub.docker.com/】
- 04,Cambricon SDK v1.7.0 【SDK等资料索取可联系Barret.Bi@wpi-group.com】
- 支持pcie x16 3.0接口的PC/Server电脑,Cambricon MLU270-F4/MLU270-S4
降版本
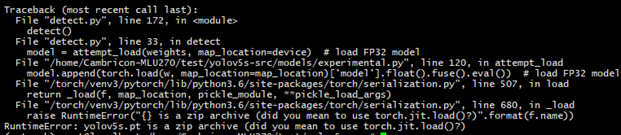
目前官方提供的Yolov5模型[pytorch版本:1.8.0,python:3.8.5]是在1.8.x的pytorch上进行训练的,但是MLU的pytorch还是1.3.0版本[MLU SDK:1.7.0,MLU PYTORCH:1.3.0]。高版本的pytorch带有zip压缩模型功能,但是在1.3.0上不支持,如果再1.3.0的版本上直接打开高版本的pt,会出现报错:
利用官方的docker来简化我们的环境搭建工作,官方docker:docker.io/ultralytics/yolov5:v4.0
创建文件run-yolov5_v4.0-pytorch-docker.sh (文件名称自定),内容如下:
#/bin/bash
set -x
export MY_CONTAINER="hub_yolov5_v4_0"
num=`docker ps -a|grep "$MY_CONTAINER"|wc -l`
echo $num
echo $MY_CONTAINER
if [ 0 -eq $num ];then
xhost +
nvidia-docker run -it --rm --gpus=all --ipc=host --name $MY_CONTAINER \
-v /home/wpi/Downloads:/home \
docker.io/ultralytics/yolov5:v4.0 /bin/bash
else
docker start $MY_CONTAINER
docker exec -ti --env COLUMNS=`tput cols` --env LINES=`tput lines` $MY_CONTAINER /bin/bash
fi
这里启动 docker.io/ultralytics/yolov5:v4.0 镜像,进入容器后,到目录/usr/src/app

修改detect.py
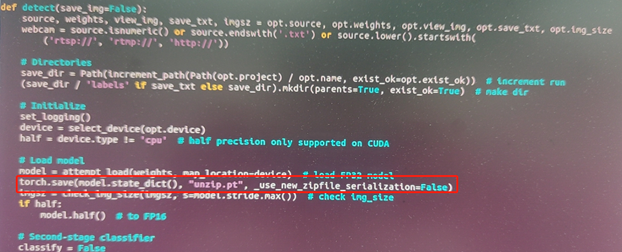
torch.save(model.state_dict(), "unzip.pt", _use_new_zipfile_serialization=False)
下载weights文件:
如果默认执行,会默认下载5.0版本的,这里我们统一用的4.0版本,为了避免出现奇怪的问题,我们手动下载4.0的版本。https://github.com/ultralytics/yolov5/releases/tag/v4.0 下载后放在当前目录的weights下。
执行python detect.py --device cpu --weights yolov5s.pt
生成unzip.pt文件,这个pt文件可以放到mlu pytorch使用。
移植过程
- 搭建环境
使用镜像:yellow.hub.cambricon.com/pytorch/pytorch:0.15.0-ubuntu16.04
-v部分可以自定义
进入docker环境后,下载yolov5:v4.0版本
cd /home/Cambricon-MLU270
git clone https://github.com/ultralytics/yolov5.git
git checkout v4.0

2. 激活MLU PYTORCH
source /torch/venv3/pytorch/bin/activate
3. 在yolov5的目录下,需要修改部分代码
打开models/experimental.py文件:
1) 头部增加 import matplotlib 和use('Agg') 两行代码引入库
2) 修改读取model代码
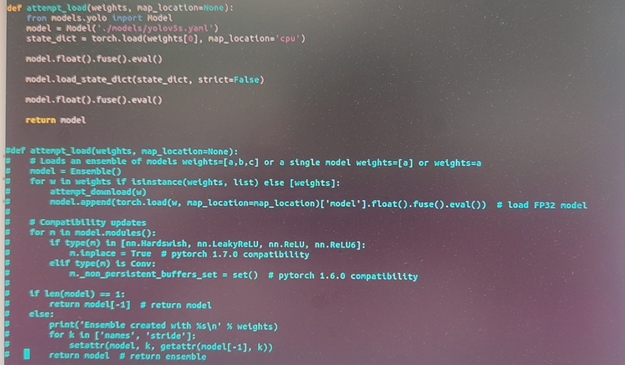
这里默认使用yolov5s,所以固定载入 ./models/yolov5s.yaml
3) 验证: python detect.py --device cpu --weights unzip.pt
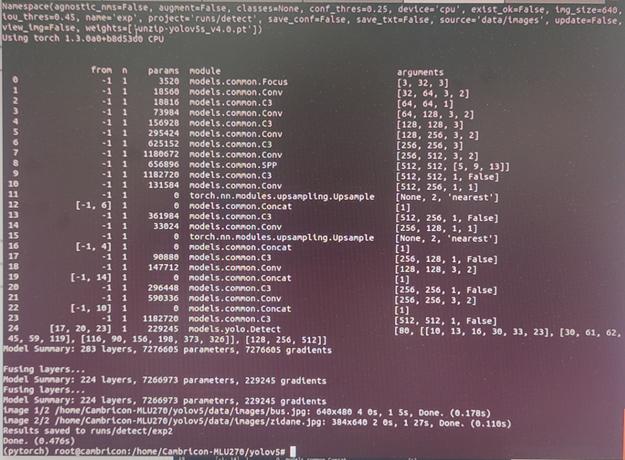
出现这个画面,说明官方的pt模型能在MLU PYTORCH上运行了。
小插曲:有的这里运行可能会报错如下问题
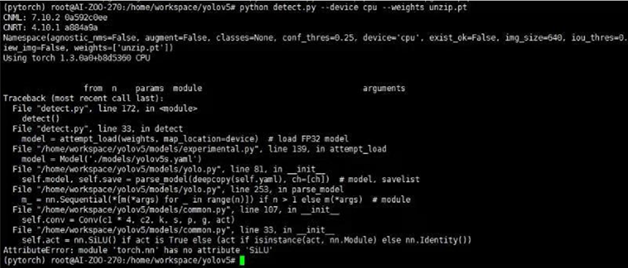
原因分析:torch1.3不支持SiLU算子。
解决方法:增加相关算子
修改/torch/venv3/pytorch/lib/python3.6/site-packages/torch/nn/modules/activation.py,添加SiLU, Hardswish激活函数如下
class Hardswish(Module): # export-friendly version of nn.Hardswish()
@staticmethod
def forward(x):
# return x * F.hardsigmoid(x) # for torchscript and CoreML
return x * F.hardtanh(x + 3, 0., 6.) / 6. # for torchscript, CoreML and ONNX
class SiLU(Module): # export-friendly version of nn.SiLU()
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
修改/torch/venv3/pytorch/lib/python3.6/site-packages/torch/nn/modules/__init__.py,注册SiLU, Hardswish激活函数
1) from .activation import 中添加SiLU, Hardswish,
2) __all__ = 中添加'SiLU', 'Hardswish',
修改完成后再执行上述的验证命令就不会报错了。
4. 模型量化
打开detect.py文件,在 Run inerence上增加代码
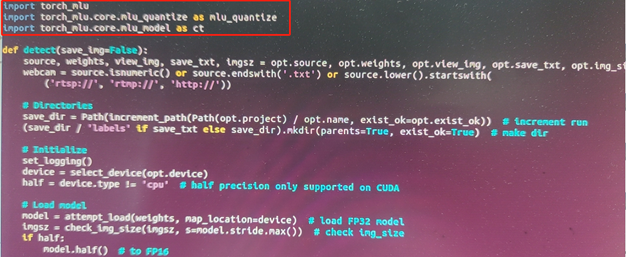
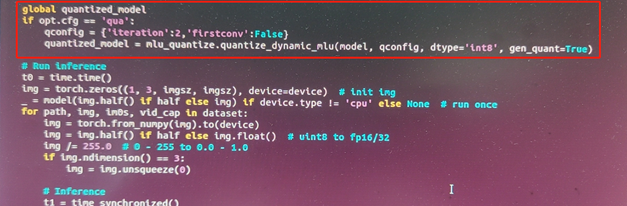
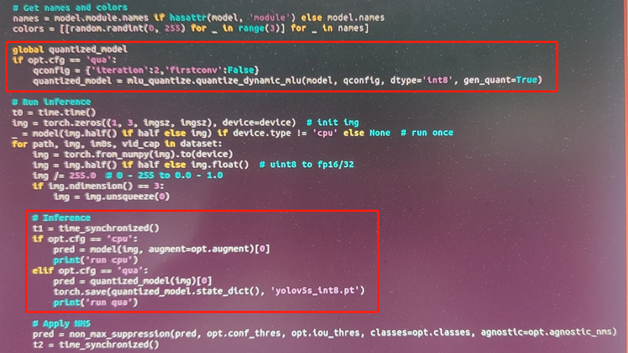
执行 python detect.py --device cpu --weights unzip.pt --cfg qua命令
torch.save(quantized_model.state_dict(), 'yolov5s_int8.pt')
这里会生成一个量化的pt文件,结果如下图所示
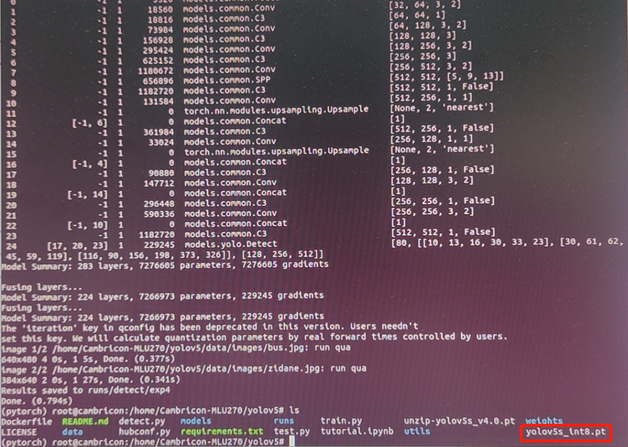
5. 逐层模式
由于每一层都需要跑在mlu上,通过打印可以看到其他层目前是能支持的,最后一层由mlu算子完成。
打开models/yolo.py,修改如下代码
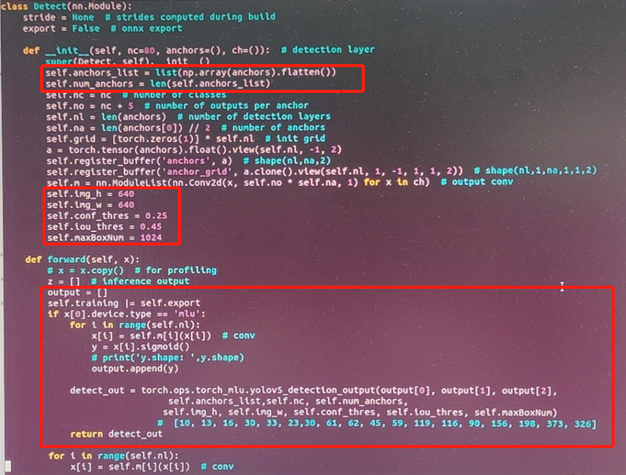
可以看到,这里将Detect类修改为mlu支持的算子 torch.ops.torch_mlu.yolov5_detection_output
detect_out = torch.ops.torch_mlu.yolov5_detection_output 这里算子是把img宽高固定为 640X640作为输入。detect.py中需要继续增加逐层运行的方式:vi detect.py
增加一个get_boxes的函数,用来从torch.ops.torch_mlu.yolov5_detection_output获取结果后画框,不再依赖cpu的获取框的后处理方式了。
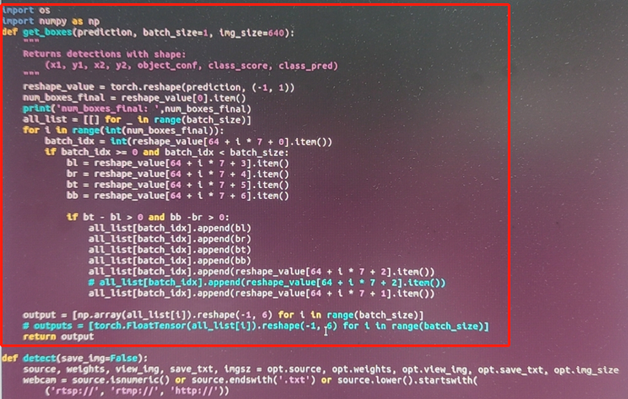
增加 mlu 的配置方式
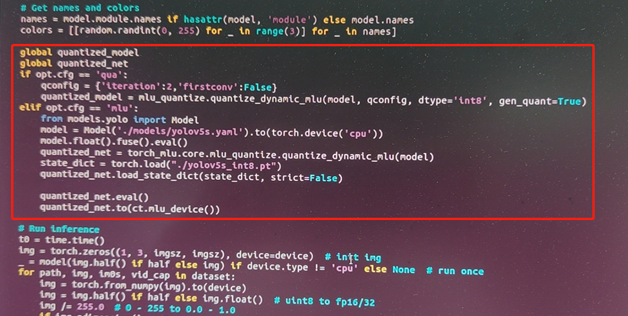
增加mlu的推理方式
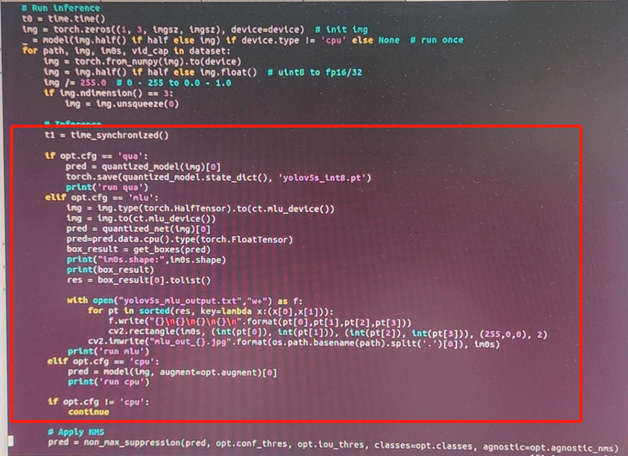
运行
python detect.py --device cpu --weights unzip.pt --cfg mlu
结果
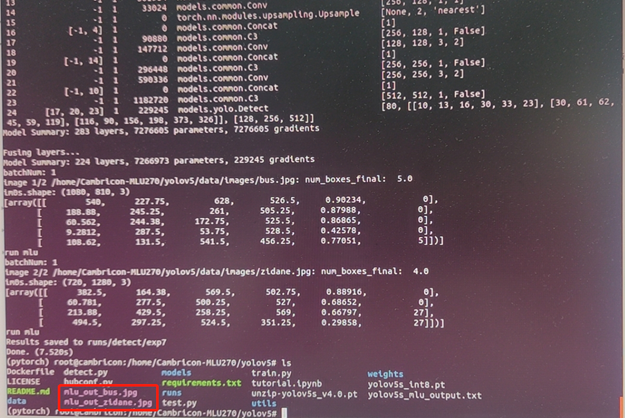
查看测试图片结果:


框不正确,通过读get_boxes源码,发现当前处理只能对640X640的输入处理,最后标框也是在640X640的图片上完成。对该图片进行缩放,并补全到640X640,再次运行结果如下


6. 融合模式
增加部分代码,如下的opt.jit部分
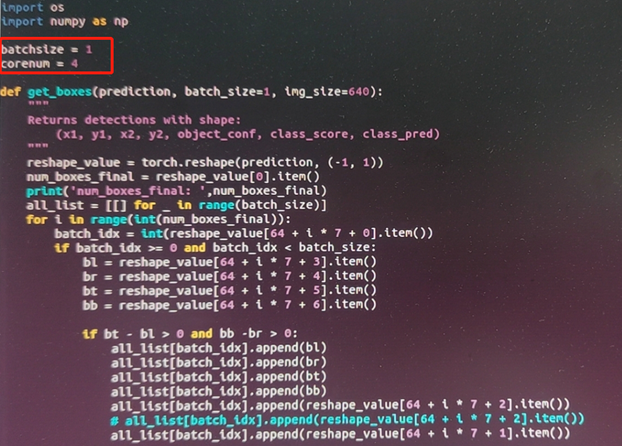
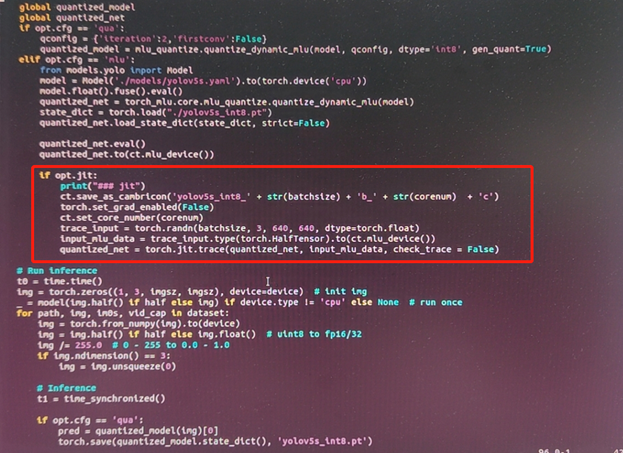
测试: 这里测试的图片,依然是选用640X640.
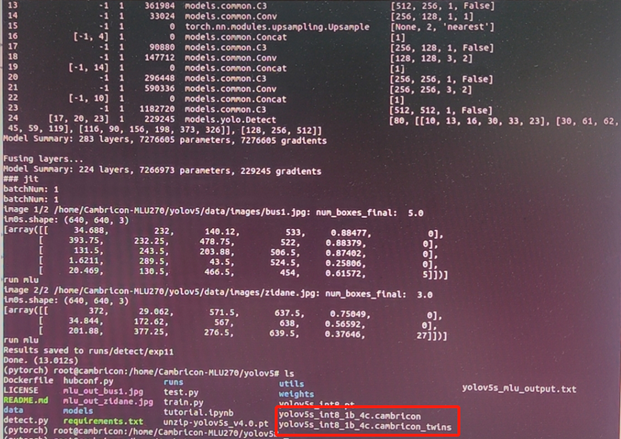
执行python detect.py --device cpu --weights unzip.pt --cfg mlu --jit True
最后得到 yolov5s_int8_1b_4c.cambricon 离线模型
补充内容
针对yolov5:v5.0升级版本,其处理方法也与上述一致,这里不再详述。
官方yolov5:https://github.com/ultralytics/yolov5.git
切换到最新的release版本
git clone https://github.com/ultralytics/yolov5.git
git checkout 5.0
使用640X640图片测试结果如下

参考文档
yolov5移植 · 语雀 (yuque.com)
评论