

零部件成本下降、中低端车竞争加剧,推动ADAS渗透率在中国市场快速提升,自主品牌ADAS装配量大幅提升。5年前在一些高端车型上才有ADAS功能。2015 年以来,电子器件成本不断下降,消费者倾向于选择安全性能更高的、配备智能驾驶辅助功能的汽车。现在中低端车型,尤其是自主品牌,ADAS的装配率已经越来越高了,尤其是FCW前方碰撞预警系统、AEB自动紧急制动系统、ACC自适应巡航、LDW车道偏离预警系统、DMS疲劳驾驶预警系统等多项功能装配率不断提高。
ADAS的渗透率快速提升来自于几方面动力:
1)ADAS相关的硬件成本近年来快速降低,例如毫米波雷达尤其是77GHz的毫米波雷达价格比五年前降低了超过50%;
2)CNCAP把一些基本的ADAS功能如AEB放入评价体系也在客观上有力推动了这些功能的普及;
3)中低端车竞争加剧,造成主流合资和自主品牌的重点车型上ADAS功能的搭载率甚至超过了一些在华销售的高端品牌车型。
预计未来中国市场智能驾驶辅助功能的渗透率将持续快速提升,中低端汽车配置的智能驾驶辅助功能项目将逐步增多。根据Strategy Analytics预测ADAS功能在我国乘用车中渗透率将从2019年的不到20%提高至70%以上;自动泊车目前车型渗透率较低,未来提升空间较大。根据汽车之家大数据统计,30万以下车型渗透率远不足20%,预计2025年可以达到50%左右的渗透率。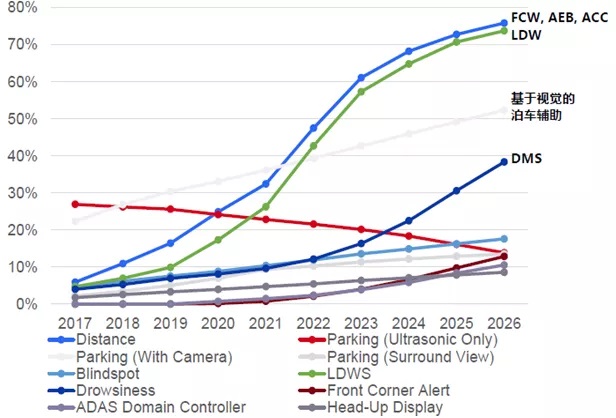
自动驾驶组成和主要技术简介
感知层:主要由激光雷达、 摄像头、高精度地图、IMU/GPS等部分构成,主要负责搜集车身周边信息;
决策层:以感知信息数据为基础,根高算力的计中心获取经过优化的驾驶决策;
执行层:基于决策层给出的驾驶决策,对制动系统、发机转向等控下达指令,负责驾驶执行;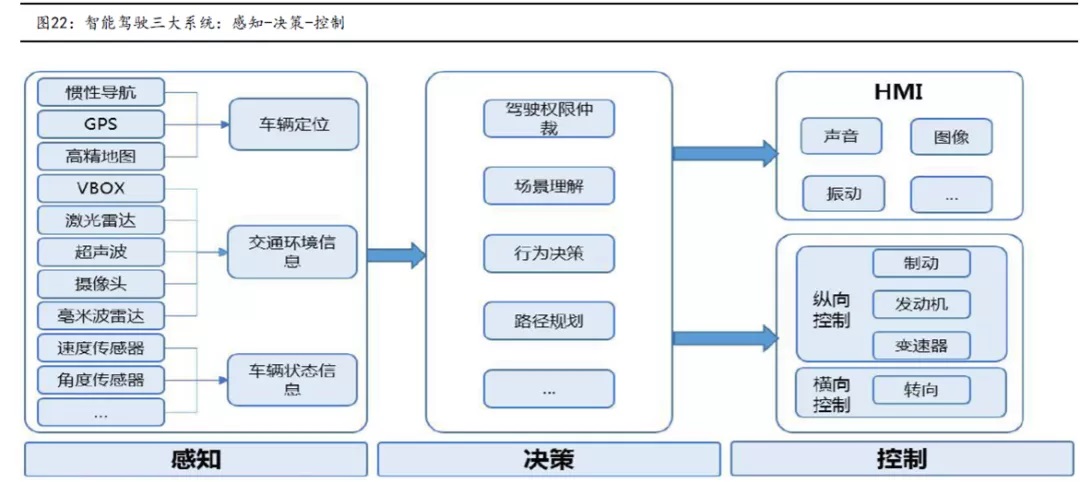
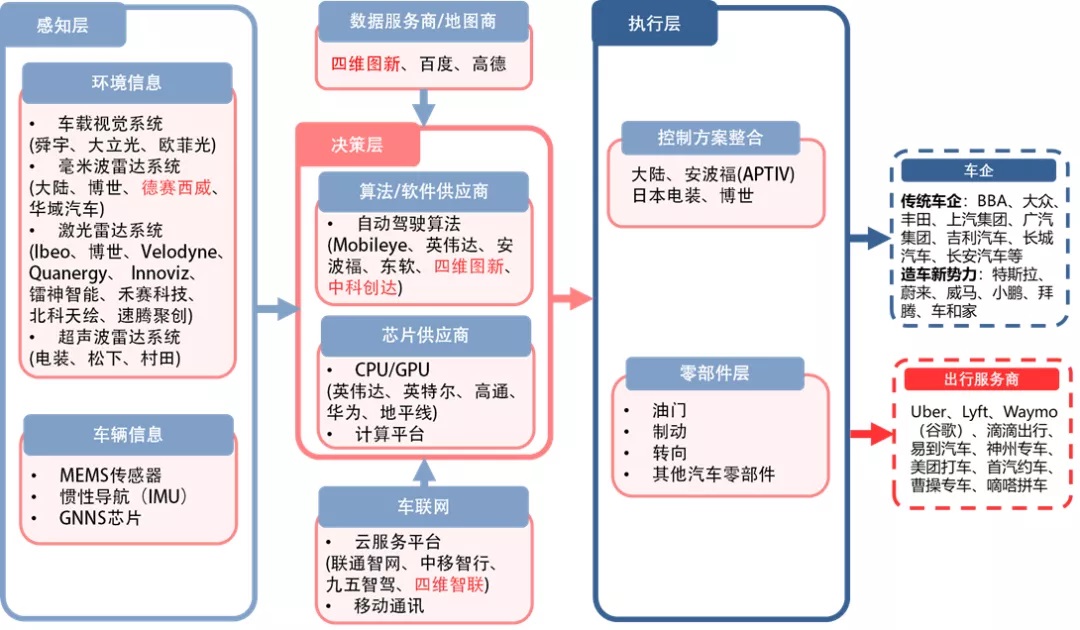
不用于智能座舱是按照Tier1 和tier2来分产业链,自动驾驶的技术层级来分的产业链,这样相对于比较清晰一些。
- 感知层的视觉系统:有舜宇、大立光、欧菲光;
- 毫米波雷达系统有大陆、博世、德赛西威、华域汽车;
- 激光雷达有 ibeo、博世、velodyne、Quanergy、innoviz、雷神智能、禾赛科技、北科天绘、速腾聚创;
- 超声波雷达系统 电装、松下、村田;
- 数据服务商/地图厂家 百度、四维图新、高德;
- 决策层有 mobileye、英伟达、安波福、东软、四维图新、中科创达;
- 芯片供应商有 英伟达、英特尔、高通、华为、地平线;
- 车联网服务平台 联通智网、中移智行、九五智驾、四维智联;
- 执行层 控制方案整合 安波福、日本电装、博世;
自动驾驶组成和主要技术简介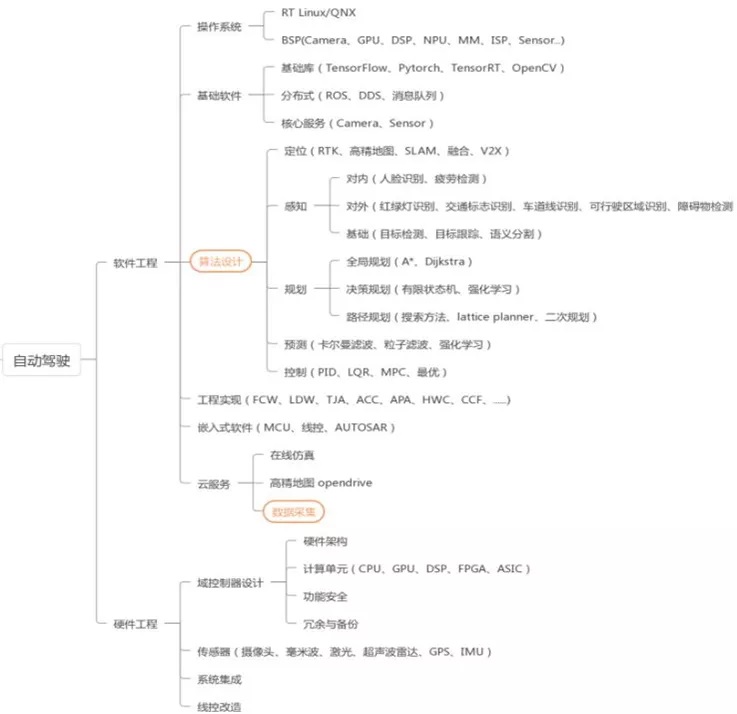
从自动驾驶各个研发环节来看,主要涉及到软件工程&硬件工程:
1)软件工程:
- 操作系统、
- 基础软件(基础库、分布式、核心服务)
- 算法设计(定为、感知、规划)
- 工程实现(FCW、LDW等)
- 云服务(仿真、高精度地图)
- 高精度地图
2)硬件工程:
- 域控制设计(硬件架构、计算单元、功能安全)
- 传感器(激光雷达、毫米波雷达、超声波雷达、摄像头、GPS、IMU等)
- 系统集成、线控改造。
供应链上游:CPU芯片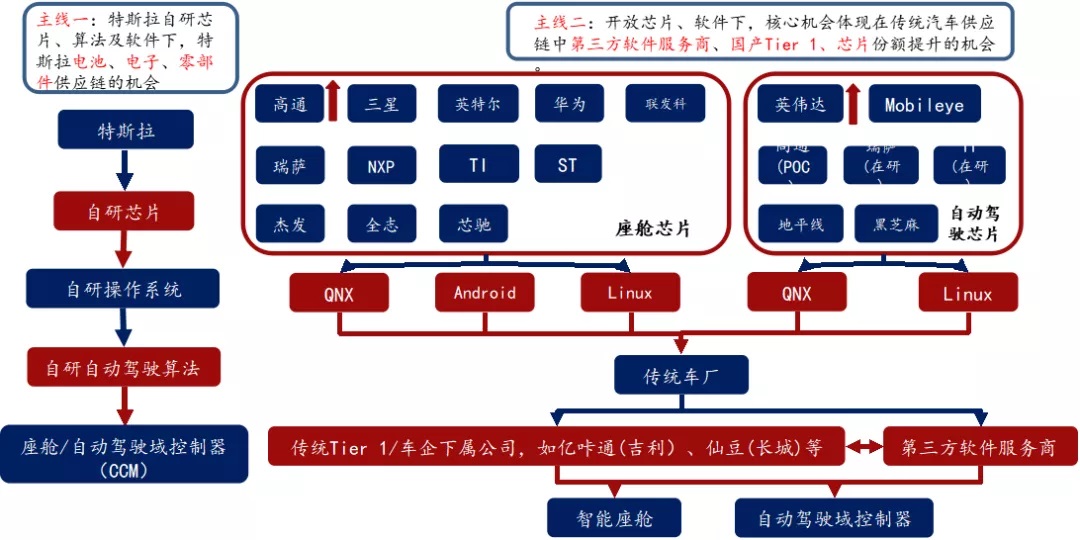
半导体、能源革命驱动的此轮汽车智能化、电动化浪潮,半导体格局反应产业链格局
座舱芯片:高通算力高、集成度高、性价比高,份额提升明显。
自动驾驶芯片
封闭生态战胜开放生态
L3+:英伟达>高通>华为
L3以下:Mobileye市占率最高,但黑盒子交付模式越来越不受车厂喜欢,未来开放模式将更受大家欢迎;地平线、黑芝麻等国产厂商有机会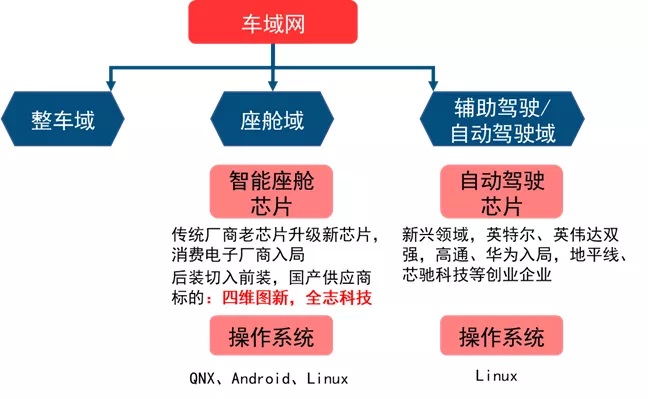
智能汽车芯片目前主要变化出现在座舱域、辅助驾驶/自动驾驶两大域控制器上。
智能座舱芯片是由中控屏芯片升级而来,目前主要参与者包括传统汽车芯片供应商以及新入局的消费电子厂商,国产厂商正从后装切入前装,包括:四维图新(杰发科技)和全志科技。
自动驾驶域控制器为电子电气架构变化下新产生的一块计算平台,目前占主导的是英特尔Mobileye和英伟达,高通、华为重点布局领域,同时也有地平线、芯驰科技等创业企业参与。
自动驾驶芯片相关性能介绍
运智能驾驶时代产业链分为三个层次:硬件公司为低层,上方是负责提供智能/连接/管理的软件层,顶层是与消费者体验相关的服务层;
大算力高性能芯片:相较于传统汽车,智能汽车数据量大增,高性能芯片成为刚需,比如流行的SA8155;
算法升级:目前硬件模块升级相对较慢,算法迭代升级则日新月异,持续优化的算法有助于降低成本,并提供更多的安全冗余
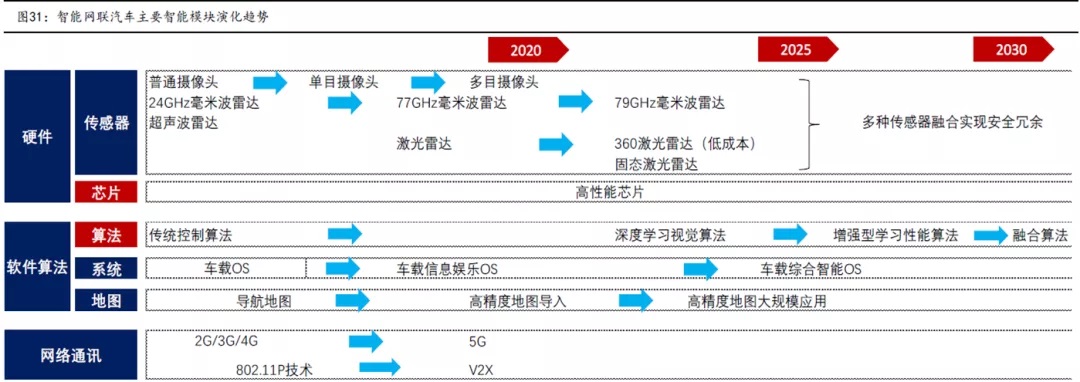
运从量产级别来看,近期量产的车型主要集中在L2+至L3级别车辆;
从硬件配置来看,相关车型主要配置有车载摄像头、毫米波雷达、超声波雷达、高算力芯片等,激光雷达则尚未配置,传感器芯片中以Mobileye相关产品居多,特斯拉采用自研的FSD;
自动驾驶适用场景中,如果是封闭路段,普遍需要高精度地图,开放路段中使用范围较小。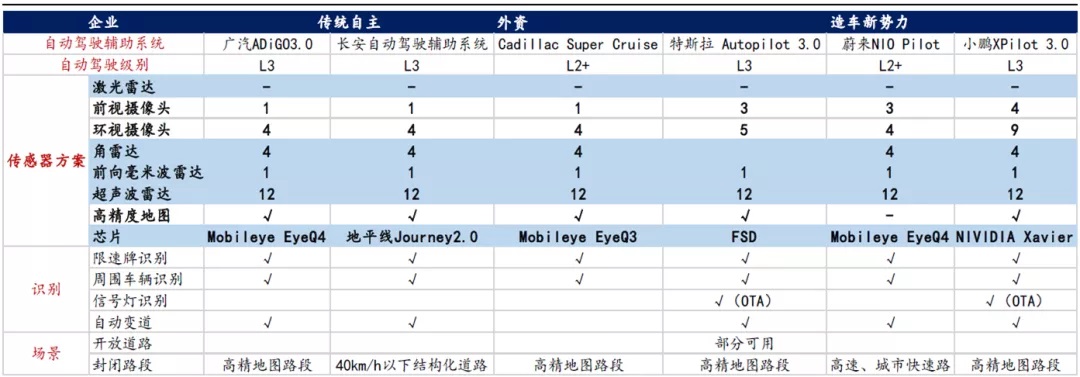
自动驾驶对于算力的要求
智能驾驶汽车涉及到传感器环境感知、高精地图/GPS精准定位、V2X信息通信、多种数据融合、决策与规划算法运算、运算结果的电子控制与执行等过程,此过程需要一个强劲的计算平台统一实时分析、处理海量的数据与进行复杂的逻辑运算,对计算能力的要求非常高。
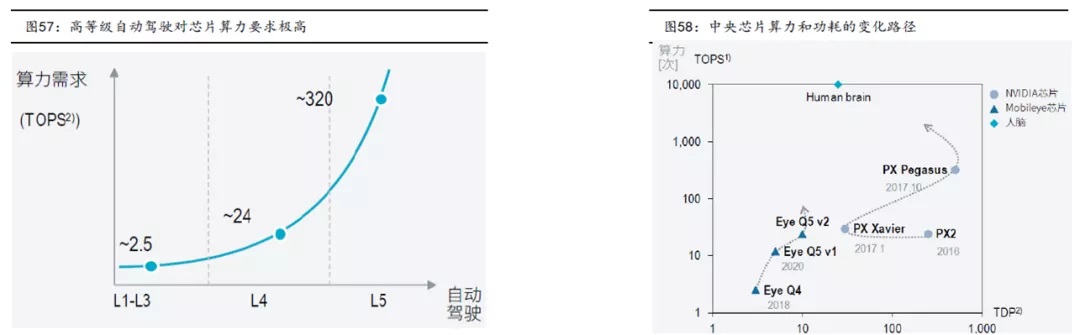
根据地平线数据披露,自动驾驶等级每增加一级,所需要的芯片算力就会呈现十数倍的上升,L2级自动驾驶的算力需求仅要求2-2.5TOPS,但是L3级自动驾驶算力需求就需要20-30TOPS,到L4级需要200TOPS以上,L5级别算力需求则超过2000TOPS。
每增加一级自动驾驶等级算力需求增长一个数量级,根据Intel推算,全自动驾驶时代,每辆汽车每天产生的数据量高达4000GB。为了更好的智能驾驶表现,计算平台成为汽车设计重点,车载半导体价值量快速提升,汽车行业掀起算力军备竞赛。以行业龙头特斯拉为例,近日媒体报道,特斯拉正与博通合作研发新款 HW 4.0 自动驾驶芯片,预计明年第四季度就将大规模量产,新一代芯片采用7nm工艺。预计HW4.0算力有望达到432 TOPS以上,超过HW3.0的三倍以上,将可用于ADAS、电动车动力传动、车载娱乐系统和车身电子四大领域的计算,成为真正的“汽车大脑”。我们来看看主流的自动驾驶芯片的算力。
这里是量产的自动驾驶芯片的算力做的对比,英伟达最新的orin的算力秒杀全场,但是还没有量产,目前看到的特斯拉单芯片算力是量产里面最强算力的,达到72 TOPS。
感知类算法,包括SLAM算法、自动驾驶感知算法;决策类算法包括自动驾驶规划算法、自动驾驶决策算法;执行类算法主要为自动驾驶控制算法;
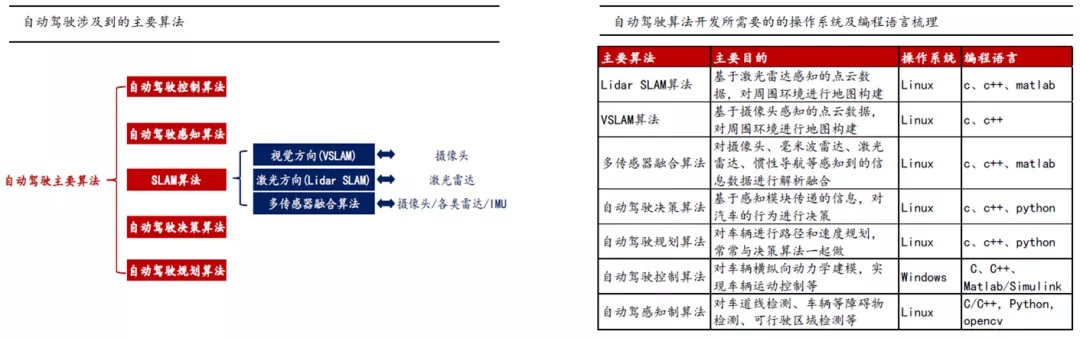
涉及到的操作系统以Linux为主,编程语言包括C/C++/PYHTON/MATLAB等;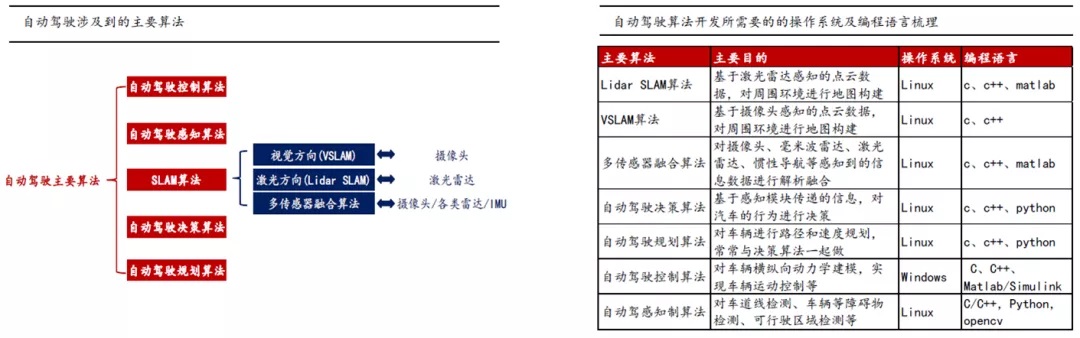
传感器融合技术:
单一类型传感器无法克服内生的缺点,我们需要将来自不同种类传感器的信息组合在一起,将多个传感器获取的数据、信息集中在一起综合分析以便更加准确可靠地描述外界环境,提高系统决策的正确性,比如典型的激光雷达+摄像头+IMU+高精度地图组合。
前融合算法:在原始层把数据都融合在一起,融合好的数据就好比是一个超级传感器,而且这个传感器不仅有能力可以看到红外线,还有能力可以看到摄像头或者RGB,也有能力看到liDAR的三维信息,就好比是一双超级眼睛,在这双超级眼睛上面,开发自己的感知算法,最后输出一个结果层的物体。
后融合算法:每个传感器各自独立处理生成的目标数据,当所有传感器完成目标数据生成后,再由主处理器进行数据融合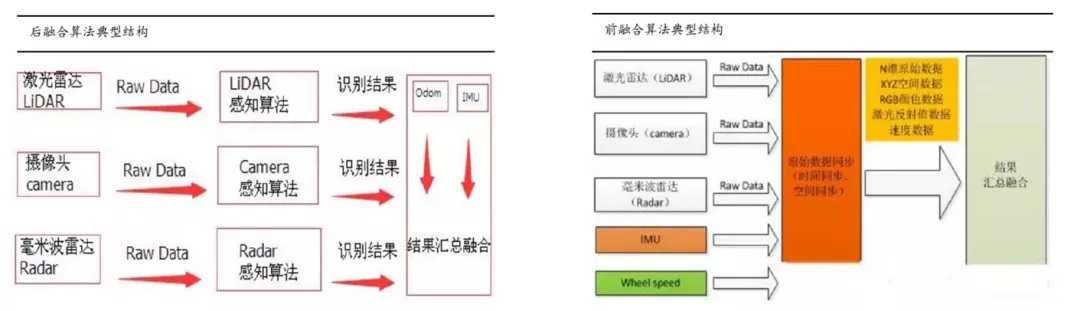
路端/云端:可以用于数据存储、模拟、高精地图绘制以及深度学习模型训练,作用是为无人车提供离线计算及存储功能,通过云平台,我们能够测试新的算法 、更新高精地图并训练更加有效的识别、追踪和决策模型。同时可支持全局信息存储和共享,互联互通业务流,对自动驾驶车实行路径优化。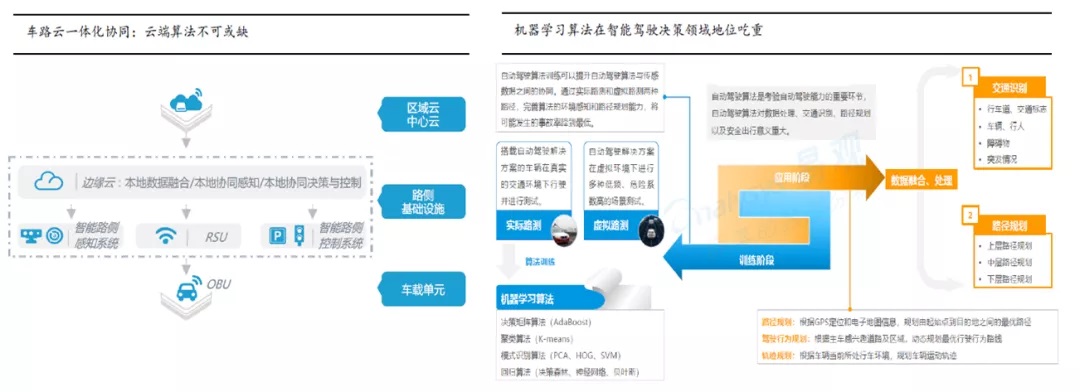
智能驾驶时代,汽车数据处理量大幅增加,对芯片性要求更高,AI芯片为主
硬件架构升级驱动芯片算力需求呈现指数级提升趋势,汽车需要处理大量图片、视频等非结构化数据,同时处理器也需要整合雷达、视频等多路数据。这些都对车载处理器的并行计算效率提出更高要求,具备AI能力的主控芯片成为主流。
数据、算力和算法是AI三大要素,CPU配合加速芯片的模式成为典型的AI部署方案,CPU提供算力,加速芯片提升算力并助推算法的产生。常见的AI加速芯片包括GPU、FPGA、ASIC三类。
GPU是单指令、多数据处理,采用数量众多的计算单元和超长的流水线,主要处理图像领域的运算加速。但GPU无法单独工作,必须由CPU进行控制调用才能工作。CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,但当需要大量的处理类型统一的数据时,则可调用GPU进行并行计算。
FPGA适用于多指令,单数据流的分析,与GPU相反,因此常用于预测阶段,如云端。FPGA是用硬件实现软件算法,因此在实现复杂算法方面有一定的难度,缺点是价格比较高。对比FPGA和GPU可以发现,一是缺少内存和控制所带来的存储和读取部分,速度更快。二是因为缺少读取的作用,所以功耗低,劣势是运算量并不是很大。结合CPU和GPU各自的优势,有一种解决方案就是异构。
ASIC是为实现特定要求而定制的专用AI芯片。除了不能扩展以外,在功耗、可靠性、体积方面都有优势,尤其在高性能、低功耗的移动端。
类脑芯片架构是一款模拟人脑的新型芯片编程架构,这一系统可以模拟人脑功能进行感知、行为和思考,简单来讲,就是复制人类大脑。
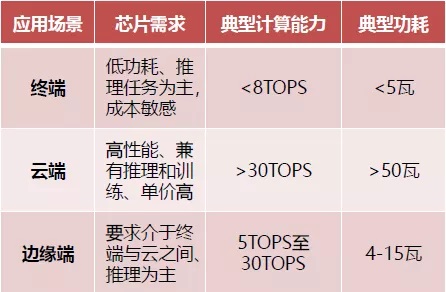
不同应用场景AI芯片性能需求和具体指标
AI芯片部署的位置有两种:云端和终端。云端AI应用主要用于数据中心,在深度学习的训练阶段需要极大的数据量和大运算量,因此训练环节在云端或者数据中心实现性价比最高,且终端单一芯片也无法独立完成大量的训练任务。
终端AI芯片,即用于即手机、安防摄像头、汽车、智能家居设备、各种IoT设备等执行边缘计算的智能设备。端AI芯片的特点是体积小、耗电少,而且性能不需要特别强大,通常只需要支持一两种AI能力。
从功能上来说,目前 AI 芯片主要有两个领域,一个是 AI 系统的 training 训练模型(主要是对深度神经网络的前期训练),另外一个是模型训练部署后,模型对新数据的 inference 推断。理论上来说 training 和 inference 有类似的特征,但是以目前的情况来说,在运算量差别大,精度差别大,能耗条件不同和算法也有差别的情况下,training 和 inference 还是分开的状态。
在 training 领域,需要将海量的参数进行迭代训练,所以芯片设计导向基本都是超高性能,高灵活性,高精度这几个方向。面向 training 的芯片一般都是在云端或者数据中心进行部署,成本大,能耗高。目前在 training 领域, Nvidia 的GPU在市场上独占鳌头,大部分的深度神经网络及项目实施都是采用 Nvidia 的GPU加速方案。同样深度学习加速市场的爆发也吸引了竞争者的入局。
Google在2015年发布了第一代TPU芯片,在2017年5月发布了基于ASIC的TPU芯片2.0版本,二代版本采用了systolic array脉动阵列技术,每秒峰值运算能力达到45TFlops。并且二代版本完善了初代TPU只能做 inference 无法 training 的问题。根据Google的披露,在自然语言处理深度学习网络中,八分之一的TPU Pod(Google自建的基于64个TPU2.0的处理单元)花费六个小时就能完成32块顶级GPU一整天的训练任务。
除了Google外,AMD也发布了基于Radeon Instinct的加速器方案,Intel则推出了 Xeon Phi+Nervana方案。在training领域,资金投入量大,研发成本高,目前竞争者主要是Nvidia GPU, Google TPU和新进入的AMD Radeon Instinct(基于GPU)和IntelXeon Phi+Nervana(基于ASIC)等。目前来看,不管是Google的TPU+tensorfow,还是其他巨头新的解决方案,想要在training端市场撼动Nvidia的地位非常困难。
相比 training 而言 inference 在计算量( 更小) , 精度要求( 更低) 和算法部署( 多种evaluation方法)上都有一定的差别,通常只需要用 training 阶段训练好的模型来对新输入 的数据输出模型结果,或者在输出结果的基础上做一些调整。比如摄像头拍到的新的人像直接输出人脸识别模型的结果,就是利用 training 好的模型做一次 inference 操作。相对 training,inference比较适合在终端部署。
如iphoneX搭载的新的A11处理器内置了双核神经网络引擎,还有类似的在自动驾驶,监控摄像头,机器人等终端设备上的 inference 芯片。从CPU到GPU,再到FPGA和最后的ASIC,计算效率依次递增,但灵活性也是依次递减的。在inference方面,除了GPU之外,ASIC和FPGA都有比较大的潜力。
目前业界在 inference 方面也越来越多地开始使用专用性更强的FPGA和ASIC平台。FPGA全称“可编程门阵列”,通过在芯片内集成大量基本的门电路,允许用户后期烧写配置文件来更改芯片功能实现可更改半定制化。FPGA在延迟和功耗方面都有显著优势,在延迟需求较高比如语音识别和图像识别方面相比GPU而言是一个更好的选择。
ASIC是专用的定制化集成电路,能在开发阶段就针对特定的算法做优化,效率很高。ASIC虽然初期成本高,但是在大规模量产的情况下有规模经济效应,反而能在总体成本上占优。因为设计完成后无法更改,故ASIC的通用性比较差,市场风险高。FPGA因为可以半定制化并且内容可更改,在通用性/兼容性方面占有优势,但是在成本,性能,能效上比,ASIC更有优势。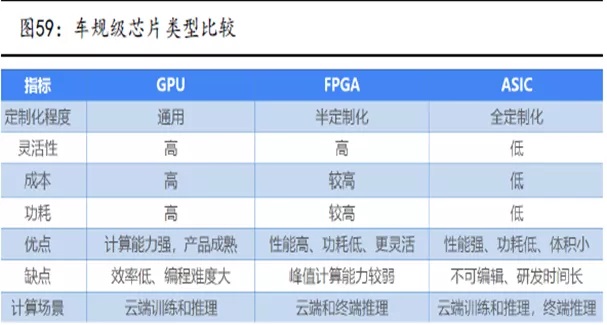
汽车主控芯片结构形式也由 MCU 向 SOC 异构芯片方向发展。
现阶段用于汽车决策控制芯片和汽车智能计算平台主要由三部分构成:
1)智能运算为主的 AI计算单元;
2)CPU单元;
3)控制单元。
主控SoC常由 CPU+GPU+DSP+NPU+各种外设接口、存储类型等电子元件组成,现阶段主要应用于座舱 IVI、域控制、ADAS等较复杂的领域。现有车载智能计算平台产品如奥迪 zFAS、特斯拉 FSD、英伟达Xavier 等硬件均主要由 AI(人工智能)单元、计算单元和控制单元三部分组成,每个单元完成各自所定位的功能。

车载AI芯片未来会非线性增长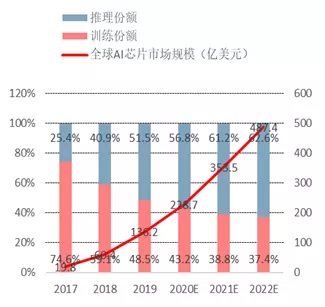
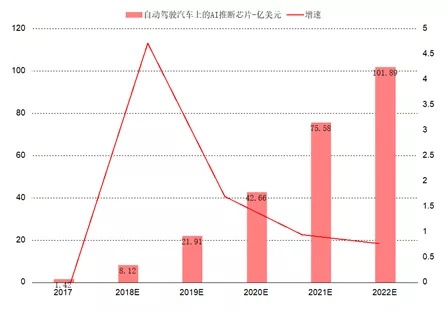
随着自动驾驶渗透率快速提升,预计车载AI芯片市场规模超过手机侧AI芯片规模。随着智能化对算力需求的指数级增长,ADAS功能逐步成为智能汽车标配,预计到2025年70%的中国汽车将搭载L2-L3级别的自动驾驶功能。观研天下预测全球自动驾驶汽车上的AI 推理芯片,其市场规模将从2017 年的1.42 亿美元,年均增长135%至2022 年的102 亿美元,相比之下手机侧AI芯片市场规模为34亿美金,汽车AI芯片市场规模远超手机侧。
部署于边缘的AI 芯片/内置单元的市场规模占比将从2017 年的21%,上升到2022年的47%。其年均增速123%,超过云端部署年均增速的75%。GPU 市场份额将从2017 年的70%下降到2022 年的39%,其主要增长动力将从数据中心算法训练,转移到自动驾驶汽车。
END