

一. 概述
此篇文章为 eIQ 系列的延伸介绍,相信各位对 NXP 所开发的 eIQ 机器学习开发环境 有一定程度上的认识了 !! 这里将介绍 eIQ 之中的一个神经网路框架,或称机器学习框架( Machine Learning Framework)。 后续将带领各位如何在 ArmNN 的框架上,使用不同的硬体处理器( CPU 或 NPU 的切换 )。如下图,文章架构图所示 !! 此架构图隶属于 i.MX8M Plus 的方案博文中,并属于机器学习内的推理引擎(Inference Engine) 的 ArmNN 部分,目前章节介绍 “ArmNN 使用介绍”
若新读者欲理解更多人工智能、机器学习以及深度学习的资讯,可点选查阅下方博文
大大通精彩博文 【ATU Book-i.MX8系列】博文索引
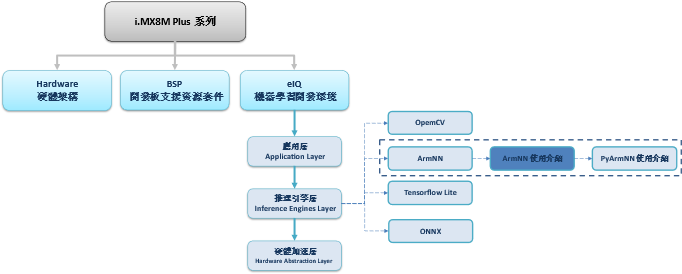
ArmNN 系列博文-文章架构示意图
二. ArmNN 介绍
目前版本 : Arm NN 21.08
ArmNN 是一套开源的机器学习推理引擎框架,由 ARM 与 Linaro 主导开发的人工智能计画,能够提供用户更简单、轻松、快速的机器学习体验。特别的是 ArmNN 并非有自己的推理引擎,而是可以运行多种深度学习模组框架的 推理引擎(inference engine) 或 委托器(delegates) ,像是 Caffe, TensorFlow, TensorFlow Lite, 以及 ONNX 。 除此之外,亦提供 CPU / GPU/ NPU 等硬体加速资源,并可以搭配 C++ 或 Python 语言进行推理 !! 能够给予 Arm 的硬体更棒的加速体验 !!
ArmNN 后端推理框架图
如下图所示,首先由各家模组 解译(parser) 完成后,将托付给 Graph builder 与 Runtime Optimizer 至各硬体设备进行优化,而后续则有三种处理方式 ; 第一种左侧路线,就是纯 CPU 的运算。第二种就是中间路线,利用 ARM Compute Library 与 ARM Neon 核心作多线程优化进行推理。而第三种则是右侧路线,委托给神经网路推理引擎(NNRT),并透过 OVXLIB 与 OpenVX driver 来启动 GPU 或 NPU 进行硬体加速来完成推理!!
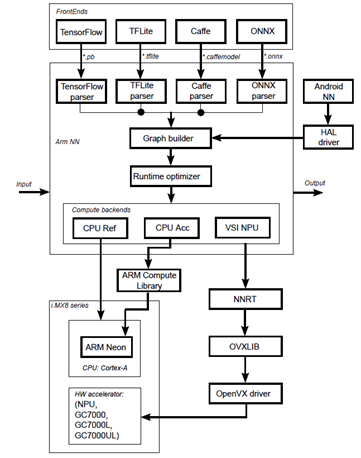
ArmNN 后端推理框架图
资料来源 : 官方网站
下列提供关于 ArmNN 之 Caffe, TensorFlow, TensorFlow Lite, ONNX 等神经网路框架的推理范例,如下列表格所示。
若欲查看更多范例,请查看 i.MX Machine Learning User's Guide.pdf 的 ArmNN 章节。
原厂提供范例 (Caffe) :
|
Arm NN binary |
Model file name |
Model definition |
Input data |
Renamed model |
|
CaffeAlexNet-Armnn |
bvlc_alexnet_1.caffemodel | |||
|
CaffeInception_BN-Armnn |
Inception-BNbatchsize1.caffemodel | |||
|
CaffeMnist-Armnn |
lenet_iter_9000.caffemodel |
{kind=link}
PS : 此范例适用于 BSP L5.10.72 之前的版本。
原厂提供范例 (TensorFlow) :
|
Arm NN binary |
Model file name |
Input data |
|
TfInceptionV3-Armnn |
Dog.jpg, Cat.jpg, shark.jpg | |
|
TfMnist-Armnn | ||
|
TfMobileNet-Armnn |
Dog.jpg, Cat.jpg, shark.jpg |
PS : 此范例适用于 BSP L5.10.72 之前的版本。
原厂提供范例 (TensorFlow Lite) :
|
Arm NN binary |
Model file name |
Input data |
|
TfLiteInceptionV3Quantized-Armnn |
Dog.jpg, Cat.jpg, | |
|
TfLiteMnasNet-Armnn |
Dog.jpg, Cat.jpg, shark.jpg | |
|
TfLiteMobilenetQuantized-Armnn |
Dog.jpg, Cat.jpg, shark.jpg | |
|
TfLiteMobilenetV2Quantized-Armnn |
mobilenet_v2_1.0_224_quant.tflite | |
|
TfLiteResNetV2-50-Quantized-Armnn |
Model not available |
N / A |
|
TfLiteInceptionV4QuantizedArmnn |
Model not available |
N / A |
|
TfLiteMobileNetSsd-Armnn |
Model not available |
N / A |
|
TfLiteResNetV2-Armnn |
Model not available |
N / A |
|
TfLiteVGG16Quantized-Armnn |
Model not available |
N / A |
|
TfLiteMobileNetQuantizedSoftmax-Armnn |
Model not available |
N / A |
{kind=link}
{kind=link}
原厂提供范例 (ONNX) :
|
Arm NN binary |
Model file name |
Input data |
|
OnnxMnist-Armnn |
t10k-images.idx3-ubyte, t10k-labels.idx1-ubyte | |
|
OnnxMobileNet-Armnn |
Dog.jpg, Cat.jpg, shark.jpg |
ArmNN 范例使用方式 (C / C++) :
直接进入开发板的 /usr/bin/armnn-21.02 底下,找到相关执行档(xxx-Armnn),操作下列指令即可使用!!
$ --data-dir=data --model-dir=models --compute=CpuAcc/VsiNpu/CpuRef--data-dir : 资料路径
--model-dir : 模组路径
--compute : CpuRef 为不启用 CPU 加速 、CpuAcc 为使用 NEON Backend 启用 CPU 加速 、 VsiNpu 为使用 NPU 或是 GPU 加速运算。
若欲查看代码编译方式,请至 i.MX Machine Learning User's Guide.pdf 的 ArmNN 章节。
三. ArmNN 范例实现
1. Object Classification DEMO (TensorFlow Lite)
说明 : 此范例使用 Arm NN - TensorFlow Lite神经网路推理框架与 MobileNet 模型进行分类物件。
实现步骤 :
(1) 于开发板系统中,建立 ArmNN 资料夹
$ cd && mkdir ArmNN
$ cd ~/ArmNN && mkdir models
$ cd ~/ArmNN && mkdir data(2) 将测试图片与新的模组传送至开发板系统
$ scp mobilenet_v1_1.0_224_quant.tflite root@xx.xx.xx.xx: ~/ArmNN/models
$ scp Dog.jpg root@xx.xx.xx.xx: ~/ArmNN/data
$ scp Cat.jpg root@xx.xx.xx.xx: ~/ArmNN/data
$ scp shark.jpg root@xx.xx.xx.xx: ~/ArmNN/data
(3) 范例之运行 CPU 使用方式
$ /usr/bin/armnn-21.08/TfLiteMobilenetQuantized-Armnn --data-dir=data --model-dir=models --compute=CpuAcc(4) 范例之运行 NPU使用方式
$ /usr/bin/armnn-21.08/TfLiteMobilenetQuantized-Armnn --data-dir=data --model-dir=models --compute=VsiNpu运行结果 :
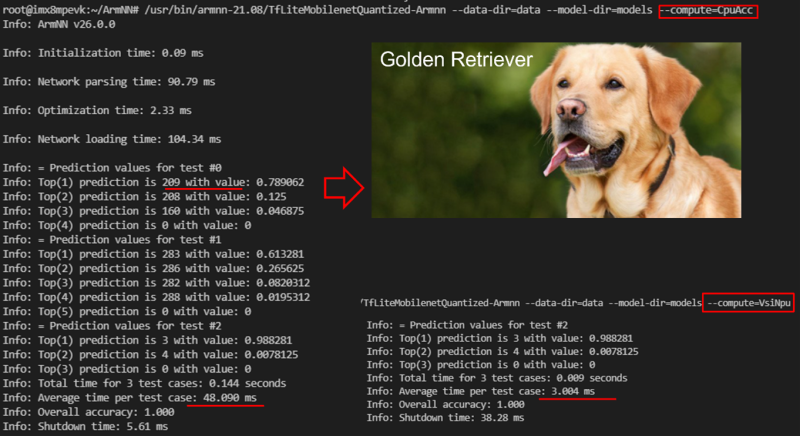
如下图所示,分类结果为 第 209 号标签的黄金猎犬(golden retriever) ,准确率为 78.9 %。
在 ArmNN 框架下,使用 CPU-ACC 运算 TF Lite模组则平均花费 48 ms,NPU 运算花费 3 ms。
*** 此范例会同时测试三张影像( Dog / Cat / Shark.jpg )。此标签分类请于该连结查看。
2. Object Classification DEMO (ONNX)
说明 : 此范例使用 Arm NN - TensorFlow Lite神经网路推理框架与 MobileNet 模型进行分类物件。
实现步骤 :
(1) 于开发板系统中,建立 ArmNN 资料夹
$ cd && mkdir ArmNN
$ cd ~/ArmNN && mkdir models
$ cd ~/ArmNN && mkdir data(2) 将测试图片与新的模组传送至开发板系统
$ scp mobilenetv2-1.0.onnx root@xx.xx.xx.xx: ~/ArmNN/models
$ scp Dog.jpg root@xx.xx.xx.xx: ~/ArmNN/data
$ scp Cat.jpg root@xx.xx.xx.xx: ~/ArmNN/data
$ scp shark.jpg root@xx.xx.xx.xx: ~/ArmNN/data
(3) 范例之运行 CPU 使用方式
$ /usr/bin/armnn-21.08/OnnxMobileNet-Armnn --data-dir=data --model-dir=models --compute=CpuAcc(4) 范例之运行 NPU使用方式
$ /usr/bin/armnn-21.08/OnnxMobileNet-Armnn --data-dir=data --model-dir=models --compute=VsiNpu运行结果 :
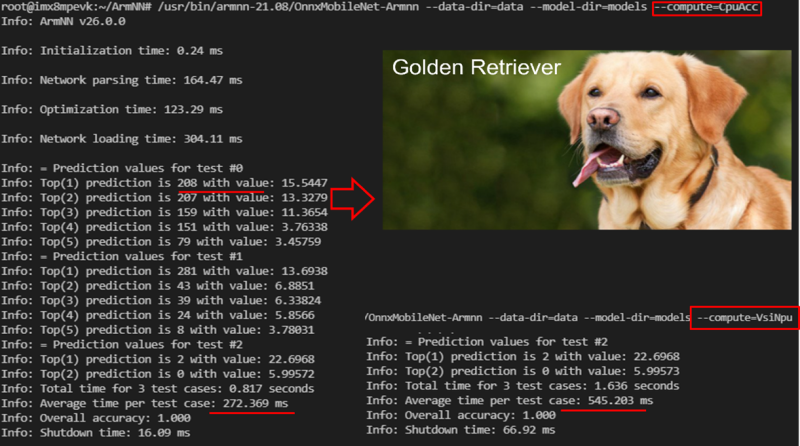
如下图所示,分类结果为 第 209 号标签的黄金猎犬(golden retriever) ,准确率为 15.54 %。
在 ArmNN 框架下,使用 CPU-ACC 运算 TF Lite模组则平均花费 272 ms,NPU 运算花费 545 ms。
目前 ONNX 的推理引擎与 AI 芯片的底层描述尚未完善故效能较差。
*** 此范例会同时测试三张影像( Dog / Cat / Shark.jpg )。此标签分类请于该连结查看。
四. 结语
上述已经介绍了 ArmNN 的使用方式,借此可以选择 TensorFlow 或是 ONNX 的神经网路框架进行推理。并可任意使用至 CPU / GPU / NPU 等加速运算芯片。在量化后的 MobileNet 最快可达到每帧 3ms 的推理速度 !! 但可惜的事,目前 ONNX 与硬体间的描述仍存在一些问题,故速度略有落差 !! 请持续关注后续的版本更新 !! 谢谢
五. 参考文件
[1] 官方网站 - i.MX Machine Learning User's Guide.pdf
[2] 官方网站 - Arm NN Developer Guide
如有任何相关 ArmNN 技术问题,欢迎至博文底下留言提问 !!
接下来还会分享更多 ArmNN 的技术文章 !!敬请期待 【ATU Book-i.MX8 系列 - ArmNN】 !!

评论