

一. 概述
本文主要将介绍恩智浦近期所推广的 AI 芯片 : 神经处理单元(Neural Process Unit, NPU)。
在本系列的章节中,将会探讨关于 NPU 的硬体特性与进阶使用的方法,带领读者更了解新颖的 AI Chip 的强大之处。若读者欲快速启用 NPU 或相关范例的话,请查阅 eIQ 或 PyeIQ 博文 !! 即可透过恩智浦所提供的 ML Framework 快速上手 !! 如下图文章架构图所示,此架构图隶属于 i.MX8M Plus 的方案博文中,并属于机器学习内的 硬体层(Hardware Layer) 的 NPU 部分,目前章节介绍 “NPU 架构探讨”。
若新读者欲理解更多人工智能、机器学习以及深度学习的资讯,可点选查阅下方博文
大大通精彩博文 【ATU Book-i.MX8系列】博文索引
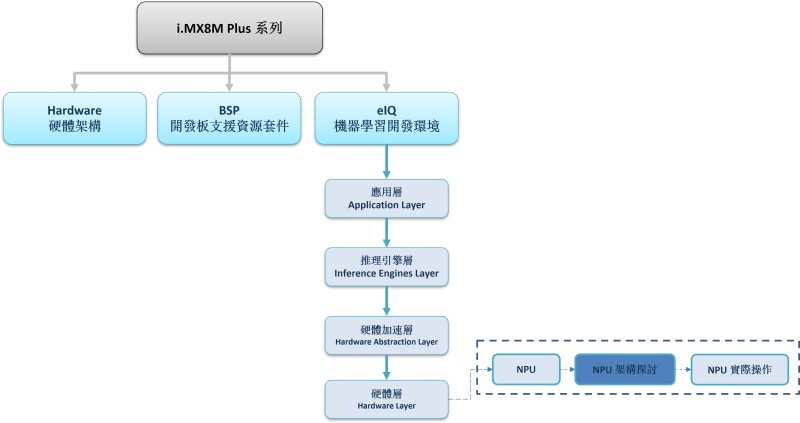
NPU 系列博文-文章架构示意图
二. NPU 架构概念
在谈论 NPU 架构之前,先来探讨图形处理器 GPU 与 神经处理器NPU 两者架构的差异为何?
所谓的 GPU 是一种拥有大量算术逻辑单元组成的并行计算架构,能够以多线程的方式来保持高存取速度与浮点数计算能力。但其缺点就是不能单独运算单一核心,使得功耗相对较高。如下图所示,在神经网路的应用里,仍是需要透过 CPU 去解析模组(Model),再将其运算拆分给 GPU完成执行运算。这里的方式较为直觉,比较像是一层一层去解析作运算,这将花费大量的读取资料时间 ! 使得 GPU 仅能扮演一个不错的加速器角色 !
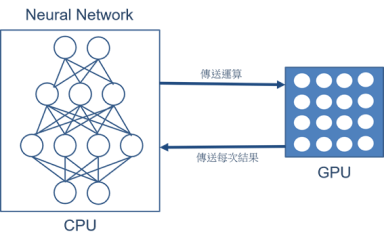
GPU 运算动作之架构示意图
资料来源 : 每日头条
另一者,NPU 是一种模拟人类神经元与突触的新颖架构,能透过一条指令完成一整组的神经元处理。
无须将每层神经元的结果传送至内存之中,是能够传递给下层记忆运算处理,竟而达到神经网路架构的处理上有着卓越优势 ! 并大幅度将低耗电等相关问题 !
如下图所示,不同于 GPU 的方式,这里 CPU 仅替 NPU 作读取模组与传送输入端的资料,后续就托付给 NPU 进行运算与推理!!
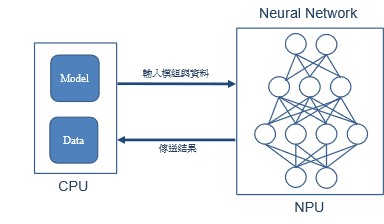
NPU 运算动作之架构示意图
资料来源 : 每日头条
以数学演算进行说明
若欲计算 D = A + B + C 的这个算式。则 GPU 仅能 tmp = A + B 后,再进行 D = tmp + C 的动作,这须读取两次记忆体资讯才能完成。对于 NPU 而言,仅须一次执行就能完成 D = A + B + C 的算式 !!
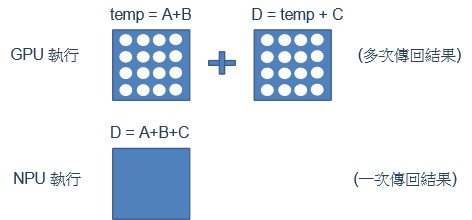
NPU 运算范例示意图
资料来源 : 每日头条
然而,在首次进行运算时,NPU 需要花费相当长的时间来建立所谓的神经元或称推理前的规划,这里所花费的时间就称作 暖开机(WarmUp) !!
此时,就能呼应到所谓的 神经网路处理(Neural Network),如同下方示意图,而暖开机所耗费的就是在建立神经网路中的参数关系,亦或是建构 神经元(蓝色圆圈) 的关系。更直白地想,就是先前替神经网路建立专属的算式或指令、甚至规划 !! 当有输入值时,就能快速演算出结果 !! 这就是 神经网路处理器(NPU) 能快速的原因之一 !!
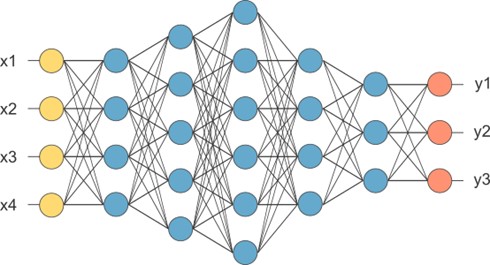
神经网路架构示意图
三. 架构探讨
简单认识 GPU 与 NPU 的架构差异后,为了让读者更清楚 NPU 的内部架构,紧接着就要介绍 NPU 的细部架构与硬体加速层的探讨。
细部架构探讨
如下图所示,为 神经处理器 NPU(Neural Processing Unit) 细节架构 :
(1) 主接面(Host Interface) :
为 AXI / AHB 接面、视觉前端程序(Vision Front End and Scheduler) 与 记忆体控制器(Memory Controller) 的通讯桥梁。
(2) 视觉前端程序(Vision Front End and Scheduler) :
是将命令传送至 神经处理模组(NPU Modules) 与 存储缓存单元(Universal Storage Cache) 的一套程序或是排程(pipeline)。
(3) 神经处理单元模块(Neural Processing Unit Modules) :
为推理应用的主要单元,是由 程序化引擎单元(Programmable Engine Unit) 与 神经网路引擎(Neural Network Engine) 两块模组构成
(4) 存储缓存单元(Universal Storage Cache) :
NPU Modules 与 Vision Front End 共享缓冲单元。
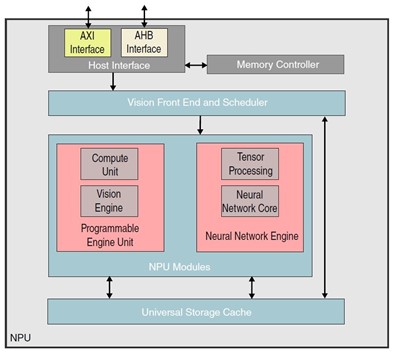
NPU 架构示意图
资料来源 : 官方网站
其中,神经处理模块(NPU Modules) 可拆分出 :
(1) 程序化引擎单元(Programmable Engine Unit)
计算单元(Compute Unit) : 为 SIMD 架构的小型处理器。
视觉引擎(Vision Engine) : 提供高级图像处理之功能。
(2) 神经网路引擎(Neural Network Engine)
张量处理(Tensor Processing) : 提供资料预处理、支援压缩和剪修与多维度的张量数组处理。
神经网路核心(Neural Network Core) : 提供整数之卷积或矩阵运算功能。
神经网路引擎(Neural Network Engine) 细部规格 :
主要应用方向为分类(Classification)、侦测(Detection)、分割(Segmentation),且能够运行 LeNet, AlexNet, VGG, GoogleLeNet 等神经网路模组架构、以及支持 RNN 递归神经网路。同时,作为 OpenVX 与 TensorFlow backend 推理引擎的基底,即可运行 TensorFlow Lite / ONNX / ArmNN / Caffe 等深度学习框架所训练出的模组…
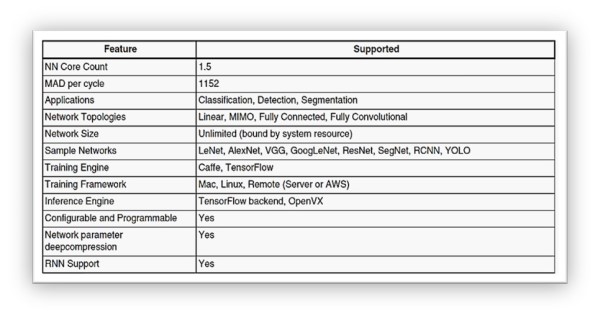
神经网路引擎细部规格
资料来源 : 官方网站
张量处理单元(Tensor Processing) 细部规格 :
能以 8 与 16 位元的整数进行张量运算处理,并支持最大与平均池化层、 ReLU 与 Leaky ReLU 激活层、正归化等神经网路架构层…
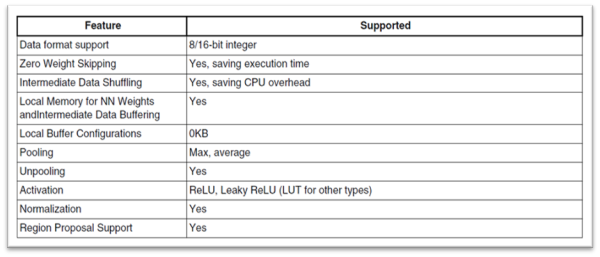
张量处理单元细部规格
资料来源 : 官方网站
除了上述架构之外,还有一个重要的 平行处理单元(Parallel Processing Unit) 架构,主要负责以平行化计算的方式来处理浮点数或半浮点数的一些运算,以及一些部分无法量化为全整数的操作层(Operator) 将由此层进行运算 !! 若欲得知各层所负责推理的单元处理器为何,请至附录查看。
平行处理单元(Parallel Processing Unit, PPU) 细部规格 :
以 单指令流多资料流(SIMD) 的方式进行操作,每次最大指令数量为 1M 个与最大 8 条资料串流进行传送,并支援及闸(AND)、或闸(OR)、是否为空值(ISNAN) 等计算方式…
PS : 在 Profiling Log 中,平行处理单元(PPU) 等同于 Shader(SH)
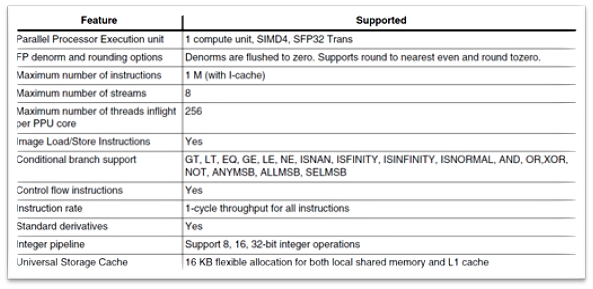
平行处理单元细部规格
资料来源 : 官方网站
硬体加速层探讨
然而,在 NXP i.MX8 系列的推理引擎架构中,不论是使用 TensorFlow Lite、ONNX 、 ArmNN 皆会透过 OVXLib 驱动 OpenVX Driver 来启动 NPU 神经网路处理器 !!
所谓 OpenVX 架构是一种介于软体层与硬体层之间的架构层,或是资料库(Lib)。换句话说,就是负责向硬体加速器或是运算器沟通的软体架构层,透过供应商所提供的指令集而达到运算效能最佳化之目的。比起熟知 OpenCL 资料库,OpenVX 所提供资源更为广阔,适用的硬体资源更不局限于图形处理器 GPU 、且支持多种硬体加速器,包括其数位信号处理器 DSP、视觉处理单元 VPU、神经网路处理器 NPU 等等 !! 可说是近年相当成熟的硬体加速资料库 !
PS : OpenVX 与 OpenCL 相同皆是以 C 语言作为主要编译语言
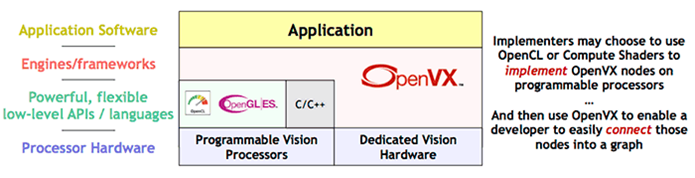
OpenVX 软体架构示意图
资料来源 : 官方网站
从 NXP i.MX8 的机器学习软体架构探讨。如下图红框所示, NXP 提供了数种硬体加速层的支援,如同 OpenVX、OpenCL 以及 Arm Compute Library 硬体加速资料库,给予使用者更有效更快速的应用方式 !! 这里可惜的事,目前官方尚未明确演示 NPU 与 OpenVX 之间的用法,细节仍待进一步钻研 !! 而一般读者或开发者仅须要透过使用上一层的 TensorFlow Lite、ONNX、 ArmNN 等开源推理引擎(Open Source Inference Engines) 来完成推理即可 !!
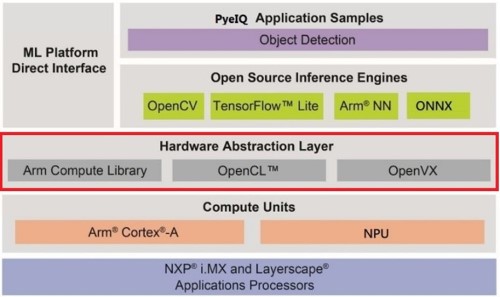
i.MX8 机器学习软体架构示意图
资料来源 : 官方网站
目前版本 : OpenVX 1.2
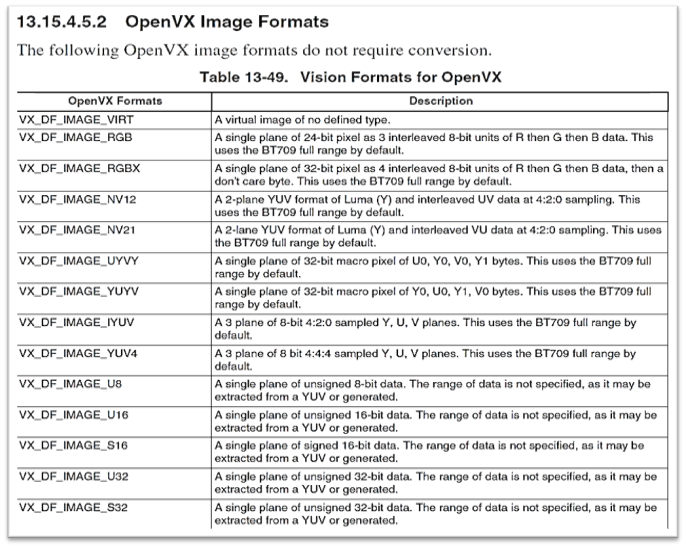
OpenVX 硬体加速相关范畴 :
硬体加速资料库 OpenVX 可以提供 NPU 载入图像时的硬体支援,并给予一些基本的影像处理资源。
如下表所示,有一系列的 3x3 滤波器、直方图、位元操作等等模块,最大遮罩大小能够为 11x11 以及 8 / 16 位元的点积运算…

OpenVX 硬体加速相关范畴 :
四. 结语
本文已向读者阐明 GPU 与 NPU 的差异以及 NPU 的细部结构一些基本概念的介绍,并说明 OpenVX 在整个推理流程上的重要性,以及 i.MX8 机器学习软体架构图等等。而本篇除了传递 NPU 相关的细节资讯外,最重要的事,就是想传达一个概念 ; “恩智浦提供了完善的开发环境,开发者仅须要专注于模组开发与机器学习框架的使用,即可快速上手 !!“ 。 此系列后续还会向读者介绍一些关于 NPU 暖开机、资讯显示等等方法 !! 敬请期待 !!
五. 参考文件
[1] 官方文件 - i.MX Machine Learning User's Guide
[2] 官方文件 - ISP and NPU
[3] 官方文件 - i.MX 8M Plus NPU Warmup Time
如有任何相关 NPU 技术问题,欢迎至博文底下留言提问 !!
接下来还会分享更多 NPU 的技术文章 !!敬请期待 【ATU Book-i.MX8 系列 - NPU】 !!

评论