

在开始介绍 MediaTek NeuroPilot 之前,我想先帮各位伙伴们科普一下什么是 Edge AI。
许多人工智能仍远在云端,且可能无法如你所愿,快速地传送到达终端。伙伴们也许会思考,为什么不让人工智能离你近些呢?
MTK将人工智能技术应用到你周边的终端装置,充分地实现终端人工智能,这意味着伙伴们无需等待,也无需上网,就能立即享受到人工智能。
使用上可以得到更快速地回应、更好的隐私保护、更多的功能。
Faster response
Better privacy
More Functionality
然而,为了优化终端人工智能,MediaTek 为神经网路运算,设计了一个全新的人工智能处理单元 APU,和 CPU 相比,它可以节省高达 95% 的电力 (SAVE 95% ENERGY CONSUMPTION),让你能有更多的时间处理更多任务
MTK还建立了一个创新的异构运算架构 (HETEROGENEOUS COMPUTING),能即时导引正确的任务到正确的位置,让每个处理器都能发挥最佳性能和最大化的能源效率,这就是MTK的终端人工智能平台 – NeuroPilot
NeuroPilot 支持业界所有主流的人工智能架构如下列所示。
Google: TENSORFLOW/TENSORFLOW LITE
AMAZON: MXNET
CAFFE
SONY: NNABLA
Other NN Frameworks
如果伙伴们是开发人员,只要开发一次,便可应用 NeuroPilot 到任何可支援的终端装置。
CROSS PRODUCT
CROSS OPERATING SYSTEM
Android / Linux / RTOS / Others
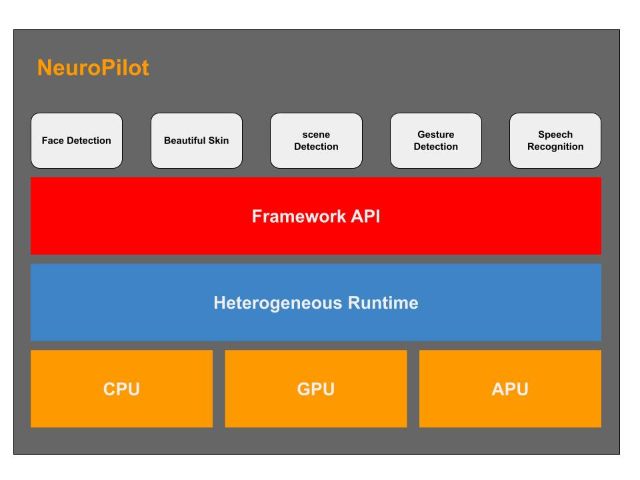
NeuroPilot 大致可分为三个层级,如下图所示,最顶层是各种应用程序,也是我们日常就能接触的一些应用,像是一些脸部识别、面部美化、场景检测、手势检测、语音识别等等。
中间层用于程序编写和异构运算,主要由软体算法所构置的,包括神经网络运行(NN Runtime), 异构运行(Heterogeneous Runtime)。
这些基于各别级别的 API 进行程序编写的框架,我们称之为 AI framewrok,像 Google 的tensorflow(Lite)、caffe、Amazon 的 MXNet、Sony 的 NNabla 等。
联发科技的 NeuroPilot 支持市面上主流且常用的所有 AI framework,意思就是说,我们的伙伴们就能够很方便地在 NeuroPilot 平台上进行程序开发,同时也能够很好地与云端对接。
再来最底层是各种硬件处理器 CPU、GPU、APU。
一般情况下,我们在处理这个 model 太大,然后想要把它缩小,做优化来讲,有几个大家比较常用的手法。
我先讲一下什么是优化,优化工具主要专注的地方是在 training 那个阶段。会把训练好的 model 来做优化。伙伴们可能会想,为什么要在 training 好的 model 来做优化呢?
这是因为我们很多AI model 在训练好的时候,其实占用很大的容量,动不动就几百兆字节。这样大小的 model 放在设备端来执行的话,可以想像,第一个跑起来会很慢,第二个是非常的耗电。所以我们会用一些手法来做一些优化,让这个 model 变比较小,比较适合在设备端来执行。
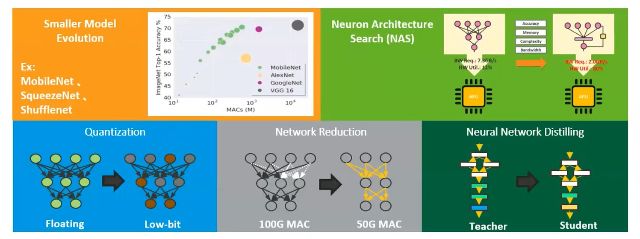
第一个手法是有些 Model 本身就比较小,如下列图示,而它的准确度,不会因为他 model 小就被影向,例如像是我们看到 MobileNet、SqueezeNet 和 Shufflenet,这几种来执行。
或是我们可以使用程式的方式去探索硬体,知道这个硬体适合什么样的 Model在什么样的硬体上会跑比较快,这种方法叫做 NAS,Neuron Architecture Search,这个手法,直接用程式去跑,看找什么样的Model比较适合的。
另外底下三个手法,它就是用程序,去达成让 Model 缩小,首先是 Quantization,或是中文我们叫做量化,这样的手法其实是去改变我们原本 Model 的储存数字和参数。
把它从 Floating point 这种比较大的格式,转换成 integer 这种比较小的格式。你可以想像,转换变小之后,它的 Model也会跟着转换缩小,缩小之后,这个 Model 就可以在设备端,跑起来比较快,比较省电。
第四个方法,这边写到是 Network Reduction, 或者是我们在软件上称做 Pruning,中文可能会叫做 剪枝,这个手法我们可以想像它是一个Model压缩的技术,它可以把一个比较大的Model,压缩成一个比较小的 Model。
另外也有人用另一个方法,它把一个大的 Model,然后再用一个小的 Model 去学这个大的Model,就是用原本training完 大的 Model,用小Model 去学它,然后最后在设备端上来执行,这是叫做 distilling 的手法。
关于 NeuroPilot 基本的介绍就到此,有兴趣的伙伴们,可以随时与我们探讨和研究,谢谢。
评论