

一. 概述
在边缘运算的重点技术之中,模组轻量化网路架构 是不可或缺的一环,如何高效的利用硬体资源来达到最佳目标,特别是在效能与准确度的衡量上,是个非常有趣的议题。此章节再来探讨深度学习热门的研究项目之一 表情识别(Facial Emotion Recognition) ,主要用于侦测人的面部表情,像是生气(angry)、厌恶(disgust)、恐惧(fear)、快乐(happy)、悲伤(sad)、惊喜(surprise), 自然(neutral) 等等,亦称 脸部表情识别(Facial Expression Recognition)。其作法通常须搭配人脸侦测来检测出人脸后,方能进行表情识别的侦测。本章节将以最基本的 卷积神经网路架构 CNN ( Convolutional Neural Network) 与 Kaggle 提供的 脸部表情(Facial Expressio) 资料来进行实现。
若新读者欲理解更多人工智能、机器学习以及深度学习的资讯,可点选查阅下方博文
大大通精彩博文 【ATU Book-i.MX8系列】博文索引
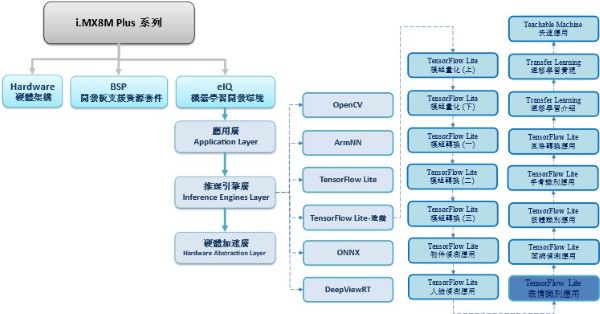
TensorFlow Lite 进阶系列博文-文章架构示意图
二. 算法介绍
神经网路架构探讨 : Convolutional Neural Network
为深度学习最基础的网路架构,如下图所示。输入影像资料后,接着 卷积层(Convolution Layer) 以逐步扫描去提取特征,并搭配 池化层(Pooling Layer) 去缩减资料量作次取样 Subsampling。
这两个架构层将会不断提取影像中的特征,即贯彻 深度(Deep) 的概念。因此要设计多少架构层,提取多少特征都是设计者可以自行决定的。
同样的,架构的深浅也直接影响到辨识率的好坏!! 在架构的最后,将利用 全连阶层(Fully Connected Layer) 去串联所有神经元来达到分类预测之目的。
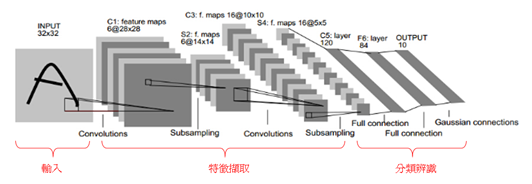
CNN 架构示意图, 图文出处- GGWithRabitLIFE 网志

CNN 各架构层作用之示意图, 图文出处- AI 知识库
三. 算法实现
这里仿照 Kaggle 的设计来完成一套简易的表情识别(Facial Emotion Recognition)。
范例连结 : https://www.kaggle.com/shawon10/facial-expression-detection-cnn/log?select=fer2013.csv
实现步骤如下:
第一步 : 开启 Colab 设定环境
%tensorflow_version 2.x第二步 : 连接 Google Drive 下载资料库
此步骤已先将所须资料库存放于 Google 云端中,请于点选连结下载。
# 连接至 google drive
from google.colab import drive
drive.mount('/content/drive')
# 新增资料夹
%cd /root
!mkdir datasets
# 下载并解压缩人脸表情资料库
%cd datasets
!unzip "/content/drive/MyDrive/Colab DataSet/Facial Expression Recognition/Facial Expression Recognition.zip"第三步 : 载入资料库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 载入资料,并存放于DataFrame资料型态中
filname = '/root/datasets/fer2013/fer2013/fer2013.csv' # 如下图所示
label_map = ['Anger', 'Disgust', 'Fear', 'Happy', 'Sad', 'Surprise', 'Neutral']
names=['emotion','pixels','usage']
df=pd.read_csv(filname,names=names, na_filter=False)
im=df['pixels']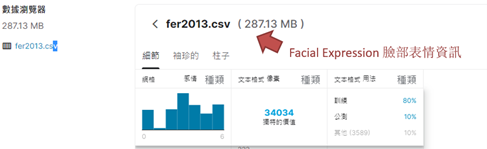
第四步 : 数据特征整理
此步骤是将所载入的资料,拆分处理成训练与测试资料、训练与测试标签。
def getData(filname):
Y = []
X = []
first = True
for line in open(filname):
if first:
first = False
else:
row = line.split(',')
Y.append(int(row[0]))
X.append([int(p) for p in row[1].split()])
X, Y = np.array(X) / 255.0, np.array(Y)
return X, Y
# 将资料切分成 训练 与 测试
from sklearn.model_selection import train_test_split
X, Y = getData(filname)
X = X.reshape(X.shape[0], 48, 48, 1)
num_class = len(set(Y))
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.1, random_state=0)
y_train = (np.arange(num_class) == y_train[:, None]).astype(np.float32)
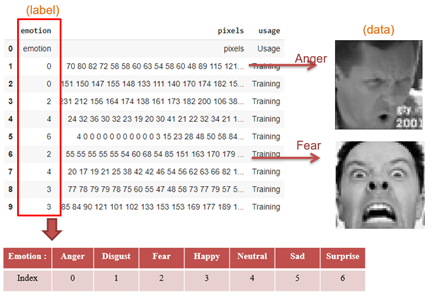
y_test = (np.arange(num_class) == y_test[:, None]).astype(np.float32)如下图所示,将 fer2013.csv 内的数据作整理。Emotion 为训练/测试标签、Pixel 为训练/测试资料。
第五步 : 建立神经网路
import tensorflow as tf
import keras
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, AveragePooling2D
from keras.layers import Dense, Activation, Dropout, Flatten
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
from keras.layers.normalization import BatchNormalization
from keras.callbacks import ModelCheckpoint
# 建立模组架构
model = Sequential()
input_shape = (48,48,1)
model.add(Conv2D(64, (5, 5), input_shape=input_shape,activation='relu', padding='same')) # 卷积层
model.add(Conv2D(64, (5, 5), activation='relu', padding='same')) ## 卷积层
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2))) # 最大池化层
model.add(Conv2D(128, (5, 5),activation='relu',padding='same')) # 卷积层
model.add(Conv2D(128, (5, 5),activation='relu',padding='same')) # 卷积层
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2))) # 最大池化层
model.add(Conv2D(256, (3, 3),activation='relu',padding='same')) # 卷积层
model.add(Conv2D(256, (3, 3),activation='relu',padding='same')) # 卷积层
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2))) # 最大池化层
model.add(Flatten())
model.add(Dense(128)) # 全连接层
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(7)) # 全连接层
model.add(Activation('softmax'))
# 最佳化参数与损失函式设定 -> 这里取用 'categorical_crossentropy' 作为损失函示、采用 Adam 的最佳化方法
model.compile(loss='categorical_crossentropy', metrics=['accuracy'],optimizer='adam')
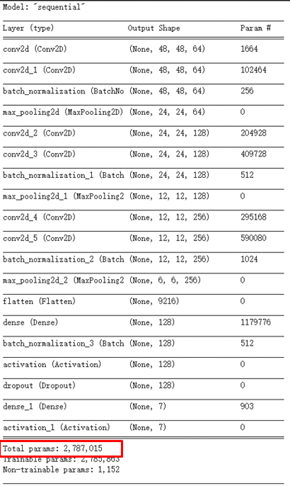
model.summary()所建置的模组架构组成如下,共产生 2,787,015 个参数。(因目前阶层少,故参数量不算多)
第六步 : 进行训练
history = model.fit(X_train_new, y_train, epochs=50, batch_size=64, validation_split=0.2)
model.save("/root/facial_expression_detection.h5") # 训练完成后, 储存模组第七步 : TensorFlow Lite 转换
import tensorflow as tf
import numpy as np
def representative_dataset_gen():
for _ in range(250):
yield [np.random.uniform(0.0, 1.0, size=(1, 48, 48, 1)).astype(np.float32)] converter = tf.compat.v1.lite.TFLiteConverter.from_keras_model_file('/root/facial_expression_detection.h5')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.float32
converter.representative_dataset = representative_dataset_gen
tflite_model = converter.convert()
with open('/root/facial_expression_detection.tflite','wb') as f:
f.write(tflite_model)
print("tranfer done!!")
※ 训练完成后,将于 /root 资料夹内产出 facial_expression_detection.tflite 档案
第八步 : Facial Emotion Recognition 范例实现 (于 i.MX8M Plus 撰写运行)
这里需搭配人脸侦测找出人脸位置,若相关模型请查看 ”人脸侦测(Face Detection) ” 章节
import cv2
import numpy as np
from tflite_runtime.interpreter import Interpreter
# 载入人脸检测器(face detector) , 解析 tensorflow lite 档案
interpreterFaceExtractor = Interpreter(model_path='mobilenetssd_uint8_face.tflite')
interpreterFaceExtractor.allocate_tensors()
input_details = interpreterFaceExtractor.get_input_details()
output_details = interpreterFaceExtractor.get_output_details()
width = input_details[0]['shape'][2]
height = input_details[0]['shape'][1]
# 载入人脸表情检测器(Facial Emotion Recognition) , 解析 tensorflow lite 档案
emotion_dict = {0: "Angry", 1: "Disgusted", 2: "Fear", 3: "Happy", 4: "Neutral", 5: "Sad", 6: "Surprised"}
interpreterFacailEmotion = Interpreter(model_path='facial_expression_detection.tflite') # 记得将模组移动至 i.MX8 平台
interpreterFacailEmotion.allocate_tensors()
input_facial_details = interpreterFacailEmotion.get_input_details()
output_facial_details = interpreterFacailEmotion.get_output_details()
facial_input_width = input_facial_details[0]['shape'][2]
facial_inpu_height = input_facial_details[0]['shape'][1]
facial_output_num = output_facial_details[0]['shape'][1]
# 载入测试影像
frame = cv2.imread('yichan.jpg')
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame_resized = cv2.resize(frame_rgb, (width, height))
input_data = np.expand_dims(frame_resized, axis=0)
# 检测出人脸
interpreterFaceExtractor.set_tensor(input_details[0]['index'], input_data)
interpreterFaceExtractor.invoke()
# 人脸位置资讯
detection_boxes = interpreterFaceExtractor.get_tensor(output_details[0]['index'])
detection_classes = interpreterFaceExtractor.get_tensor(output_details[1]['index'])
detection_scores = interpreterFaceExtractor.get_tensor(output_details[2]['index'])
num_boxes = interpreterFaceExtractor.get_tensor(output_details[3]['index'])
# 检索每张人脸特征
for i in range(1):
if detection_scores[0, i] > .5: # 预测值大于 0.5则显示
x = detection_boxes[0, i, [1, 3]] * frame_rgb.shape[1]
y = detection_boxes[0, i, [0, 2]] * frame_rgb.shape[0]
cv2.rectangle(frame, (x[0], y[0]), (x[1], y[1]), (0, 255, 0), 2) # 框出人脸位置
# 撷取人脸,并重新调整大小
roi_x0 = max(0, np.floor(x[0] + 0.5).astype('int32'))
roi_y0 = max(0, np.floor(y[0] + 0.5).astype('int32'))
roi_x1 = min(frame.shape[1], np.floor(x[1] + 0.5).astype('int32'))
roi_y1 = min(frame.shape[0], np.floor(y[1] + 0.5).astype('int32'))
# 感兴趣区域
roi = frame_rgb[ roi_y0 : roi_y1, roi_x0 : roi_x1, : ]
# 转灰阶影像
roi = cv2.cvtColor(roi, cv2.COLOR_BGR2GRAY)
roi_resized = cv2.resize(roi, (facial_input_width, facial_inpu_height))
input_facial_data = np.expand_dims(roi_resized, axis=0)
input_facial_data = np.expand_dims(input_facial_data, axis=3) # 调整表情检测器之输入张量
# 检测出人脸表情
interpreterFacailEmotion.set_tensor(input_facial_details[0]['index'], input_facial_data)
interpreterFacailEmotion.invoke() # 进行推理
# 标记文字(表情)
text_x = roi_x0
text_y = min(np.floor( roi_y0 - 10 + 0.5 ).astype('int32'), frame.shape[0])
emotion = interpreterFacailEmotion.get_tensor(output_facial_details[0]['index']) # 输出各别类别的机率
cv2.putText(frame, emotion_dict[np.argmax(emotion)],\
( text_x, text_y ), cv2.FONT_HERSHEY_SIMPLEX, 2, (0, 0, 255), 3, cv2.LINE_AA)
cv2.imshow('Emotion', frame)
cv2.waitKey(0)
cv2.destroyAllWindows()Facial Emotion Recognition 实现结果呈现
如下图所示,成功检测出脸部表情。
在 i.MX8M Plus 的 NPU 处理器,推理时间(Inference Time) 约 3 ms。


※ 该模型准确度仅有 7 成,且易受到人脸侦测所给予的输入资讯。故效果有限,仍须改良。
四. 结语
脸部表情识别(Facial Expression Recognition) 是一套人脸侦测的延伸应用,适用于人脸侦测后,再次侦测该项目。目前运行在 i.MX8MP 的 Vivante VIP8000 NPU,其推理时间可达每秒 3 ms 的处理速度,约 330 张 FPS 。而此范例是以最基础的 CNN 模组架构 与 Kaggle 的资料库来建置此应用,因此蛮推崇初学者可以常去 Kaggle 开发各式各样的 AI 应用。下一章节将会介绍人脸侦测的延伸应用之一的 面网侦测(Face Mesh) !! 敬请期待 !!
五. 参考文件
[1] SSD: Single Shot MultiBox Detector
[2] SSD-Tensorflow
[3] Single Shot MultiBox Detector (SSD) 论文阅读
[4] ssd-mobilenet v1 算法结构及程式码介绍
[5] Get models for TensorFlow Lite
[6] widerface-to-tfrecord
[7] FACIAL EXPRESSION RECOGNITION IN THE WILD USING RICH DEEP FEATURES
[8] ImageNet Classification with Deep Convolutional Neural Networks
[9] Facial Expression Database
[10] Convolution Neural Network 卷积神经网路
[11] 卷积神经网络 – CNN
[12] Facial Expression Detection (CNN)
如有任何相关 TensorFlow Lite 进阶技术问题,欢迎至博文底下留言提问 !!
接下来还会分享更多 TensorFlow Lite 进阶文章 !!敬请期待 【ATU Book-i.MX8系列 – TFLite 进阶】 !!
评论