

近期,劲爆亮相的 ChatGPT 着实让人们眼前一亮,让普罗大众也“亲密”体验了人工智能(AI)的神奇魔力,窥见了智能未来的璀璨前景之一斑。
然而,就在这离生活愈来愈近的 AI 让人们对未来充满无限憧憬、满怀激动的同时,也有冷静的分析指出,诸如 ChatGPT 等 AI 规模应用也是一个“吞金兽”,其带来的不仅仅是让人急呼“AI 算力告急”的算力消耗;更有从云端、边缘到终端广泛 AI 应用场景,使得 IT 运营环境日益复杂和多样,让各种 AI 方案在异构平台获得便捷、易用且有效优化成为急迫的需求。
异构计算,主要指不同类型的指令集和体系架构的计算单元组成的系统的计算方式,在云数据中心、边缘计算场景等有着广泛应用。
异构计算的兴起与工作负载密切相关,在能有效发挥异构计算优势的应用场景中,人工智能场景可谓是典型的代表场景之一,不管是深度学习训练,还是深度学习推理,都会进行大量矩阵运算,需要异构计算提供更有力支撑;而随着 AI 应用快速走向边缘,由此引致的云边端协同,对异构计算提出了更高要求。计算平台在提升自身算力水平的同时,也需要通过提供优化策略,帮助用户更好地提升 AI 方案的性能,助力 AI 应用降本增效。
腾讯云创新打造 TACO Kit 套件,为 AI 应用提供异构加速
为帮助广大用户应对日益复杂的异构环境给AI应用带来的挑战,腾讯云创新推出计算加速套件 TACO Kit (TencentCloud Accelerated Computing Optimization Kit) ,通过在异构硬件平台上提供全栈式的软硬件解决方案的模式,为 AI 方案设计者、AI 开发人员以及 AI 使用者构建全新的异构计算加速软件服务,助其借助多元化异构、高性能加速框架、离线虚拟化技术以及灵活的商业模式,轻松驾驭多元算力,助力 AI 应用全方位、全场景降本增效。
作为异构加速服务的入口,TACO Kit 内置 AI 推理加速引擎 TACO Infer,能针对 AI 应用中不同的训练和服务框架、个性的优化实践和使用习惯、各异的软件版本和硬件偏好,以计算加速、无感接入和鲁棒易用的特性和优势,帮助用户一站式解决 AI 模型在生产环境中部署与应用的痛点。
TACO Infer 引擎具备的功能特性包括:
■ 无感集成:可跨平台透明适配 CPU、GPU、NPU 等异构芯片;尊重用户使用习惯,无需改变模型源格式;无需进行 IR(Intermediate Representation,中间表示)转换,对无显式算子结构模型友好;
■ 基于原生框架 Runtime:可基于多种流行原生框架,包括 TensorFlow、PyTorch、ONNXRuntime 等运行;可基于框架原 Runtime 构建,并可充分利用框架自定义的扩展机制;
■ 无缝对接服务框架:包括 TF Serving、Triton 以及 TorchServe 等。
基于以上特性,无论在何种场景中,用户在硬件平台上部署 AI 应用,都只需要进行简单的前端交互,就能让 TACO Kit 在后台以最佳模式启动工作负载,并获得更优的推理性能。
而这一优异推理性能的获得,离不开英特尔和腾讯云面向 TACO Kit 开展的深度协作加持。具体讲,就是将英特尔® Neural Compressor 集成到 TACO Kit 之中,来大幅提升 AI 推理性能,加速各类 AI 应用便捷高效落地。
英特尔® Neural Compressor 提供优化支持,助力 TACO Kit 加速推理
英特尔® Neural Compressor 是英特尔开源的神经网络模型压缩库,不仅面向如量化、修剪以及知识提取等主流模型压缩技术,提供了跨多个深度学习框架的统一接口,还具有以下模型性能调优特性:
■ 具备由精度驱动的自动化调整策略,帮助用户快速获得最佳量化模型;
■ 可使用预定义的稀疏性目标生成修剪模型,实现不同的权重修剪算法;
■ 能够从更大的网络(“教师”)中提取知识用于训练更小的网络(“学生”),实现更小的精度损失。
英特尔和腾讯云协作,通过插件的方式将英特尔® Neural Compressor 集成到 TACO Kit,让 TACO Kit 充分利用英特尔® Neural Compressor 的优势特性。如图二所示,利用量化压缩技术来为不同的深度深度框架(如 TensorFlow、PyTorch、ONNXRuntime 等)提供统一的模型优化 API,便捷实现模型推理优化(由 FP32 数据类型量化为 INT8 数据类型)。同时,也可以利用压缩库内置的精度调优策略,根据不同的模型内部结构生成精度更佳的量化模型,帮助用户大幅降低模型量化的技术门槛,并有效提升 AI 模型的推理效率。
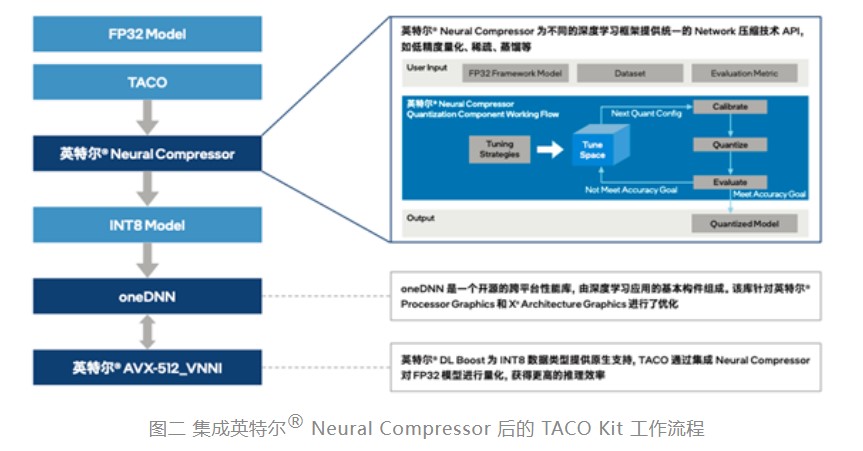
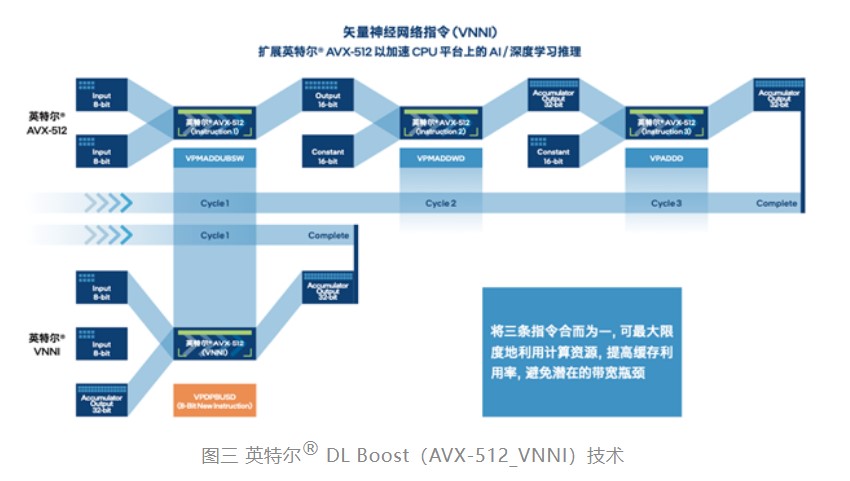
在云端部署时,量化后的模型可通过英特尔® 至强® 可扩展平台内置的英特尔® DL Boost,来获得有效的硬件加速和更高的推理效率。以指令集中的 vpdpbusd 指令为例,以往需要 3 条指令(vpmaddubsw、vpmaddwd、vpaddd)完成的 64 次乘加过程,现在仅需 1 条指令(vpdpbusd)即可,并能够消除运行过程中的处理器饱和问题,再辅之以乘加过程中的中间数值直接从内存播送,可使得处理性能达初始 FP32 模型的 4 倍2。这无疑为 TACO Kit 加速推理,进而帮助用户在异构环境更高效地构建和部署 AI 提供了关键助力
方案验证显真实性能,展异构 AI 加速优势
集成英特尔® Neural Compressor 后的 TACO Kit 的性能究竟有何等惊艳提升呢?实践最有发言权,数据最有说服力。套件打造完成后,英特尔与腾讯云一起选取了多种被广泛应用的自然语言处理深度学习模型,对 TACO Kit 性能加速进行了验证测试。
测试中,各个深度学习模型在通过 TACO Kit 进行优化后,使用英特尔® Neural Compressor 进行 INT8 量化及性能调优,推理性能加速结果令人满意。如图四所示3,在保持精度水平基本不变的情况下,各深度学习模型的推理性能均获得显著提升,提升幅度从 55% 到 139% 不等,在其中的 bert-base-uncased-mrpc 场景中,推理性能更是达到了基准值的 2.39 倍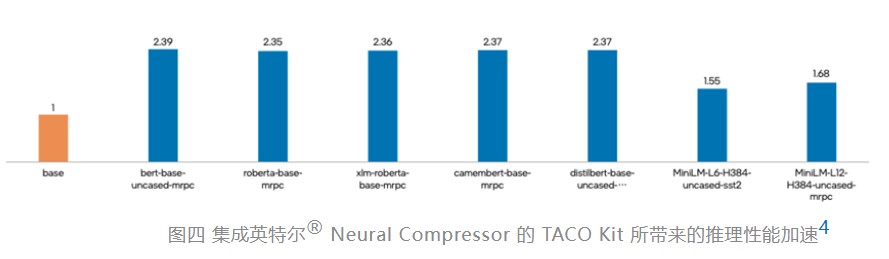
对 TACO Kit 引入英特尔® Neural Compressor 获得的大幅性能加速,腾讯云异构计算专家级工程师叶帆直言,这一合作成果能帮助不同角色的用户在异构硬件平台上获得便捷、易用且经过有效优化的 AI 加速能力,助力 AI 应用实现全方位、全场景的降本增效。而英特尔® Neural Compressor 是 TACO Kit 中 AI 推理负载获得充分性能加速的有效技术保证。
基于这一成果,英特尔和腾讯云也将面向未来继续深化合作,通过融合硬件厂商优化算子、自研 AI 编译技术升级等措施,驱动 TACO Infer 在软硬件兼容性和性能上不断迭代优化。同时,双方还计划进一步将第四代英特尔® 至强® 可扩展平台及其内置的深度学习加速技术与腾讯计算加速套件 TACO Kit 相融合,借助新平台更为澎湃的算力输出与深度学习加速新技术,为用户提供更加高效可用的异构 AI 加速能力,进而在推动 AI 走向更广泛应用的同时,助力应对多模态大模型等对算力提出的更严峻挑战,驱动智能应用向纵深化演进,为经济社会的高质量发展提供强劲数字生产力。
评论