

► 前言
要学习AI但硬体计算资源有限,可以从高维度数据中提取关键特征,或如何降低数据的维度以节省计算资源,这就是自编码器(AutoEncoder)发挥作用的地方。通过编码器和解码器的结构,AutoEncoder能够将输入数据压缩成较低维度的表示,同时尽可能地重构出原始数据。本篇博文,我们将介绍AutoEncoder及其优点及缺点,透过PyTorch 搭建一个简单的 AutoEncoder范例。
► 介绍
AutoEncoder是一种人工神经网路,主要用于无监督学习和特征学习。它可以将输入数据压缩成较低维度的表示,然后再将其解压缩成一个与原始数据相似的输出。
AutoEncoder 架构图如下: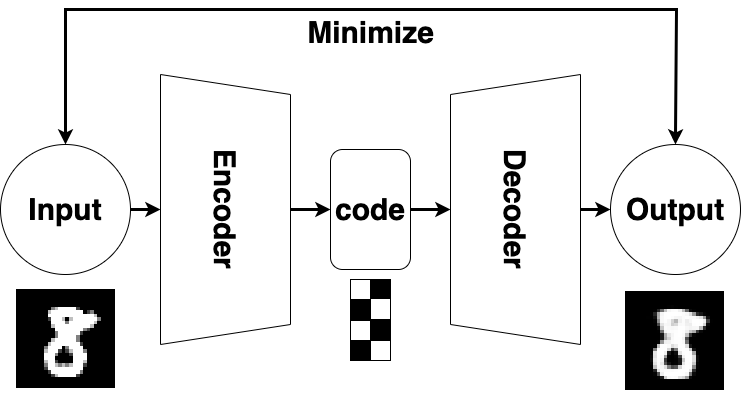
AutoEncoder架构分成两大部分:编码器(Encoder)和解码器(Decoder)。
- 编码器(Encoder):编码器将输入数据转换为较低维度的表示。
- 解码器(Decoder):解码器则将编码的表示转换回原始输入数据。
AutoEncoder的训练过程涉及最小化重构误差,即重构的输出与原始输入之间的差异。通常使用重构误差的平方差(如均方差)作为损失函数,并使用反向传播算法进行优化。
AutoEncoder能够学习数据的重要特征,并在解码过程中生成近似的输入数据。这使得AutoEncoder应用包括特征提取、去噪、降维和生成模型等。通过适当的维度减少,它可以帮助降低数据的复杂性,提高效能和计算效率,并能够生成与训练数据相似的新数据样本,如图像、音频等。
► AutoEncoder优点
- 数据的降维,减少计算量和存储空间。
- 数据的去噪,通过重建输入来恢复原始信号。
- 数据的生成,通过采样隐藏表示来产生新的数据。
- 数据的特征学习,通过提取隐藏表示来获得数据的抽象特征。
► AutoEncoder缺点
- 可能会过度压缩数据,导致信息的丢失或失真。
- 可能会过度拟合数据,导致泛化能力差或无法处理异常值。
- 可能会难以训练,尤其是当隐藏层很深或很宽时,需要调整多个超参数和正则化项。
- 可能会难以解释,尤其是当隐藏表示是非线性或高度非结构化时,需要使用可视化或其他方法来理解其含义。
► 程式码范例
使用 PyTorch 搭建一个简单的 AutoEncoder 模型的程式码示例,它可以对MNIST数字图像进行重建:
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# 设定超参数
batch_size = 128
num_epochs = 10
learning_rate = 0.001
hidden_size = 64 # 编码的大小
# 加载MNIST数据集
transform = torchvision.transforms.ToTensor() # 将图像转换为张量
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 定义Autoencoder模型
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
# 编码器
self.encoder = nn.Sequential(
nn.Linear(28*28, 256),
nn.ReLU(),
nn.Linear(256, hidden_size),
nn.ReLU()
)
# 解码器
self.decoder = nn.Sequential(
nn.Linear(hidden_size, 256),
nn.ReLU(),
nn.Linear(256, 28*28),
nn.Sigmoid()
)
def forward(self, x):
# 将输入张量展平为一维向量
x = x.view(-1, 28*28)
# 获得编码
code = self.encoder(x)
# 获得重建
out = self.decoder(code)
# 将输出张量恢复为原始形状
out = out.view(-1, 1, 28, 28)
return out
# 创建模型实例并移动到设备(CPU或GPU)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")model = Autoencoder().to(device)
# 定义损失函数和优化器
criterion = nn.MSELoss() # 使用均方误差作为损失函数
optimizer = optim.Adam(model.parameters(), lr=learning_rate) # 使用Adam作为优化器
# 训练模型
for epoch in range(num_epochs):
train_loss = 0.0 # 纪录训练集上的损失
for data in train_loader:
inputs, _ = data # 只需要图像,不需要标签
inputs = inputs.to(device) # 移动到设备
optimizer.zero_grad() # 清零梯度
outputs = model(inputs) # 前向传播
loss = criterion(outputs, inputs) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
train_loss += loss.item() # 累加损失
print(f'Epoch {epoch+1}, Train loss: {train_loss/len(train_loader):.4f}') # 打印平均训练损失
# 测试模型并可视化结果
test_loss = 0.0
with torch.no_grad(): # 不需要计算梯度
for data in test_loader:
inputs, _ = data
inputs = inputs.to(device)
outputs = model(inputs)
loss = criterion(outputs, inputs)
test_loss += loss.item()
print(f'Test loss: {test_loss/len(test_loader):.4f}')
# 选择10张图像并显示它们的原始和重建版本
num_images = 10
images = inputs[:num_images]
outputs = outputs[:num_images]
# 显示结果
fig, axes = plt.subplots(nrows=2, ncols=num_images, figsize=(15,4))
for i in range(num_images):
axes[0][i].imshow(images[i].squeeze().cpu().numpy(), cmap='gray')
axes[0][i].axis('off')
axes[1][i].imshow(outputs[i].squeeze().cpu().numpy(), cmap='gray')
axes[1][i].axis('off')
plt.show()
► 结果显示

► 小结
透过以上介绍相信大致上已经了解AutoEncoder的效果,希望本文能为你提供启发和指导,让你能够在实际应用中充分发挥AutoEncoder的应用,若还有不了解的部分可以看参考资料的网站,本篇博文就到这,下次见。
► 参考资料
► Q&A
问:AutoEncoder是一种有监督学习还是无监督学习模型?
答:AutoEncoder是一种无监督学习模型。它不需要标注的目标变量来进行训练,而是通过最小化输入与重构输出之间的误差来学习数据的特征。
问:AutoEncoder的工作原理是什么?
答:工作原理是通过将输入数据编码为较低维度的表示,然后从该表示中解码重构出原始输入数据。它由编码器和解码器组成,并透过最小化重构误差来学习数据的特征和结构。
问:AutoEncoder的应用有哪些?
答:包括特征提取、降维、去噪和生成模型等。它可以帮助从数据中提取重要特征、减少数据的维度、去除噪声,还可以用于生成新的数据样本,如图像、音频等。
问:AutoEncoder与主成分分析(PCA)有什么关联?
答:有一定的关联。它们都可以用于数据的降维,但AutoEncoder在某些情况下可以学习到比PCA更强大的非线性特征表示。AutoEncoder的编码器和解码器组成了一个神经网络,它具有更强的拟合能力,可以捕捉到数据中更复杂的特征。
问:AutoEncoder是否可以用于有标注数据的监督学习?
答:虽然AutoEncoder是一种无监督学习模型,但它也可以与监督学习相结合。例如,可以使用AutoEncoder进行无监督的特征学习,然后将编码表示作为输入喂入一个监督学习模型,以进行后续的监督学习任务。
评论