

ChatGPT 着实让人们眼前一亮,大众也“亲密”体验了人工智能(AI)的神奇魔力,窥见了智能未来的璀璨前景之一斑。然而,就在这离生活愈来愈近的 AI 让人们对未来充满无限憧憬、满怀激动的同时,也有冷静的分析指出,诸如 ChatGPT 等 AI 规模应用也是一个“吞金兽”,其带来的不仅仅是让人急呼“AI 算力告急”;更有从云端、边缘到终端广泛 AI 应用场景,使得 IT 运营环境日益复杂和多样,让各种 AI 方案在异构平台获得便捷、易用且有效优化成为急迫的需求。
异构计算:主要指不同类型的指令集和体系架构的计算单元组成的系统的计算方式,在云数据中心、边缘计算场景等有着广泛应用。
异构计算的兴起与工作负载密切相关,在能有效发挥异构计算优势的应用场景中,人工智能场景可谓是典型的代表场景之一,不管是深度学习训练,还是深度学习推理,都会进行大量矩阵运算,需要异构计算提供更有力支撑;而随着 AI 应用快速走向边缘,由此引致的云边端协同,对异构计算提出了更高要求。计算平台在提升自身算力水平的同时,也需要通过提供优化策略,帮助用户更好地提升 AI 方案的性能,助力 AI 应用降本增效。
英特尔和腾讯云协作,通过插件的方式将英特尔® Neural Compressor 集成到 TACO Kit,让 TACO Kit 充分利用英特尔® Neural Compressor 的优势特性。利用量化压缩技术来为不同的深度深度框架(如 TensorFlow、PyTorch、ONNXRuntime 等)提供统一的模型优化 API,便捷实现模型推理优化(由 FP32 数据类型量化为 INT8 数据类型)。同时,也可以利用压缩库内置的精度调优策略,根据不同的模型内部结构生成精度更佳的量化模型,帮助用户大幅降低模型量化的技术门槛,并有效提升 AI 模型的推理效率。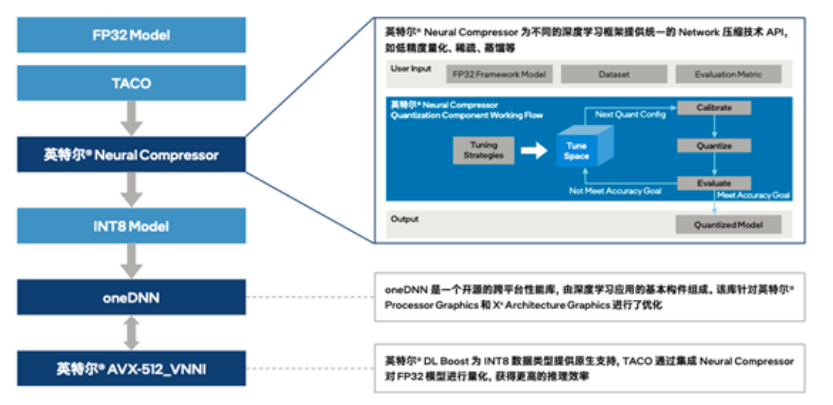
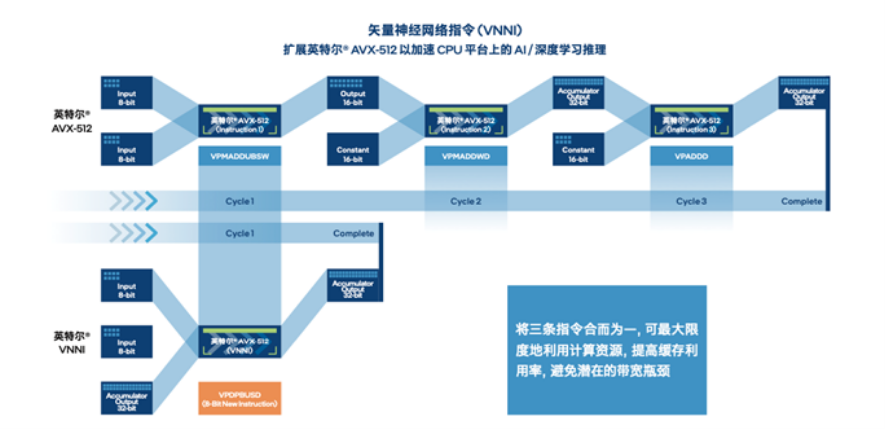
在云端部署时,量化后的模型可通过英特尔® 至强® 可扩展平台内置的英特尔® DL Boost,来获得有效的硬件加速和更高的推理效率。以指令集中的 vpdpbusd 指令为例,以往需要 3 条指令(vpmaddubsw、vpmaddwd、vpaddd)完成的 64 次乘加过程,现在仅需 1 条指令(vpdpbusd)即可,并能够消除运行过程中的处理器饱和问题,再辅之以乘加过程中的中间数值直接从内存播送,可使得处理性能达初始 FP32 模型的 4 倍2。这无疑为 TACO Kit 加速推理,进而帮助用户在异构环境更高效地构建和部署 AI 提供了关键助力。
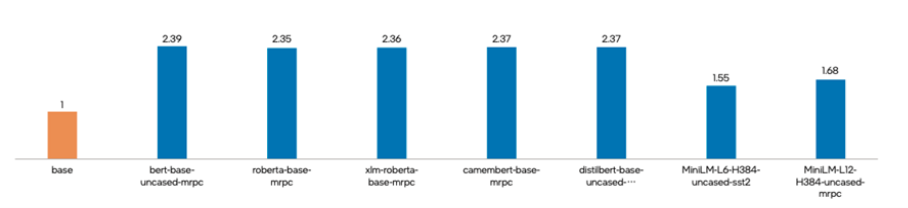
集成英特尔® Neural Compressor 后的 TACO Kit套件打造完成后,英特尔与腾讯云选取了多种被广泛应用的自然语言处理深度学习模型,对 TACO Kit 性能加速进行了验证测试。
测试中,各个深度学习模型在通过 TACO Kit 进行优化后,使用英特尔® Neural Compressor 进行 INT8 量化及性能调优,在保持精度水平基本不变的情况下,各深度学习模型的推理性能均获得显著提升,提升幅度从 55% 到 139% 不等,在其中的 bert-base-uncased-mrpc 场景中,推理性能更是达到了基准值的 2.39 倍。
基于这一成果,英特尔和腾讯云也将面向未来继续深化合作,通过融合优化算子、自研 AI 编译技术升级等措施,驱动 TACO Infer 在软硬件兼容性和性能上不断迭代优化。同时,双方还计划进一步将第四代英特尔® 至强® 可扩展平台及其内置的深度学习加速技术与腾讯计算加速套件 TACO Kit 相融合,借助新平台更为澎湃的算力输出与深度学习加速新技术,为用户提供更加高效可用的异构 AI 加速能力,进而在推动 AI 走向更广泛应用的同时,助力应对多模态大模型等对算力提出的更严峻挑战。
评论