

域控制其中最核心的是主芯片,一般会采用一颗或多颗高性能的SOC。SOC是System on Chip的缩写,就是在单块芯片上集成多个微处理器、模拟IP核、数字IP核和存储器等部件,比如CPU、GPU、DSP、ISP、Codec、NPU、Modem等模块。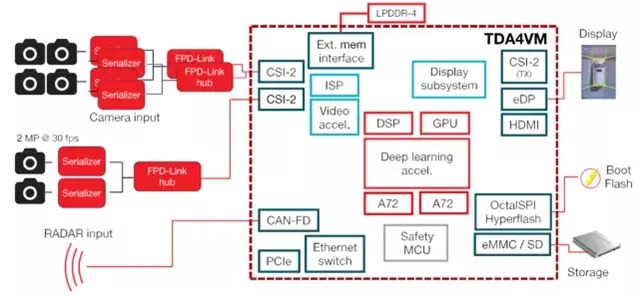
这些单元,在一套总线系统的连接下,构成了一个系统。大家所熟知的各种手机SOC芯片,如苹果的A系列、高通的骁龙系列、华为的麒麟系列,或者各类的AI SOC芯片,车载领域的各种SOC芯片,都逃不出以上范式。虽然都是同一范式,但是由于使用的场景不同,各个芯片的侧重点不太一样:
娱乐系统芯片,其实和消费电子几乎一模一样,关注音频、视频、显示、图像等、Modem等。
自动驾驶芯片,注重高性能计算,一般配备有强大的NPU、GPU、DSP等。自动驾驶芯片重要指标
中央控制器作为自动驾驶核心部件,作为自动驾驶的“大脑”端,通常需要外接多个摄像头、毫米波雷达、激光雷达,以及IMU等设备,完成的功能包含图像识别、数据处理等。因此,其需要具备多传感器融合、定位、路径规划、决策控制、无线通讯、高速通讯的能力,因而从始至终牵动着整个处理及控制命脉。
这里需要注意的是,由于自动驾驶传感器对于驾驶辅助系统的复杂度影响力(主要表现在计算能力、传输带宽、存储能力等)几乎是成倍的增加,特别是侧视摄像头的加入导致需要预处理的视频数据成倍的增加,同时,激光雷达的加入又不断地生成千万级的待处理点云信息,这就对其自动驾驶控制器计算性能及算法能力提出了比较大的需求,这也使得我们需要对自动驾驶控制器芯片选型单独提出的需求。
由于要完成大量运算,域控制器一般都要匹配一个核心运算力强的处理器,能够提供自动驾驶不同级别算力的支持,其运行时期的信息交换速度、算法计算速度、存储能力等均受到其内部控制芯片的影响。对于自动驾驶控制器芯片选型而言,主要考虑如下一些技术要求参数信息来进行方案设计。
1)算力:
自动驾驶的实现,需要依赖环境感知传感器对道路环境的信息进行采集,将采集到的数据传送到汽车中央处理器进行处理,用来识别障碍物、可行道路等,依据识别结果,规划路径、制定车速,自动控制汽车行驶。整个过程需要在一瞬间完成,延时必须要控制在毫秒甚至微秒级别,才能保证自动驾驶的行驶安全。
要完成瞬时处理、反馈、决策规划、执行的效果,对中央处理器的算力要求非常高。在自动驾驶中,最耗费算力的当属视觉处理,占到全部算力需求的一半以上,且自动驾驶级别每升高一级,对计算力的需求至少增加十倍。L2级别需要2个TOPS的算力,L3需要24个TOPS的算力,L4为320TOPS,L5为4000+TOPS。
第一部分通常是GPU或TPU,承担大规模浮点数并行计算需求,主要用于环境感知和信息融合,包括摄像头、激光雷达等传感器信息的识别、融合、分类等,如Xavier的GPU单元、升腾310。
第二部分大多为ARM架构,类似于CPU,主要负责逻辑运算和决策控制,处理高精度浮点数串行计算。
目前来看单颗芯片的算力最大的是英伟达的orin-X芯片,200TOPS算力,能效比最高的是地平线6.4FTOPS/W。
光有算力还不够,考虑汽车应用的复杂性,汽车处理器还需要同时考虑算力利用率、是否通过车规和安全标准等。算力理论值取决于运算精度、MAC的数量和运行频率。如下表示了一种典型的单帧算力计算方式:
理论算力是根据Net卷积层的乘法运算累加得出,卷积层中的每次乘加(MAC)算成两个OPS,卷积运算量占DL NET的90%以上,其它辅助运算或其它层的运算忽略不计,SSD所有卷积层乘法运算总数是40G MACs,所以理论算力是80GOPS。
真实值和理论值差异极大,考虑其它运算层,硬件实际利用率要高一些。决定算力真实值最主要因素是内存( SRAM和DRAM)带宽,还有实际运行频率(即供电电压或温度),还有算法的batch尺寸。
2)能效比:
对于车载AI芯片来说,算力指标重要,能效比更重要。在传统芯片行业,PPA(算力、功耗和面积)是最经典的性能衡量指标。因为现在汽车自动驾驶对算力的追求,业界往往会把峰值算力当作衡量AI 芯片的主要指标。
地平线提供一个新的方法用以评估芯片的AI真实性能——MAPS (Mean Accuracy-guaranteed Processing Speed,在精度有保障范围内的平均处理速度),针对应用场景的特点,在精度有保障的前提下,包容所有与算法相关的选择,评估芯片对数据的平均处理速度。
MAPS评测方法,关注真实的用户价值,将每颗芯片在'快'和'准'这两个关键维度上的取舍变化直观地展现出来,并在合理的精度范围内,评估芯片的平均处理速度。这个方法具有可视化和可量化的特点。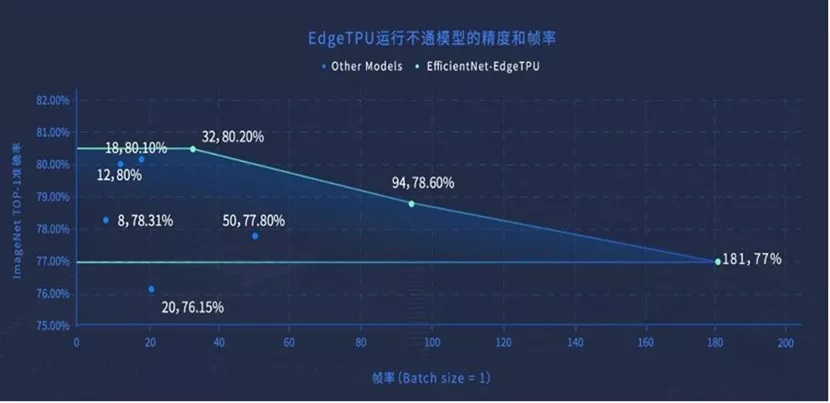
地平线致力于打造极致AI能效,芯片设计上能效比行业领先。未来一辆自动驾驶车辆平均每天产生600-1000 TB的数据计算,仅2000辆自动驾驶车辆产生的数据量超过2015年我们整个文明一天数据用量,大规模设备端部署需要成本效率。
要实现大规模部署,尤其在汽车初始售价逐步下降的情况下,车载AI芯片需要充分考虑芯片的能效比。地平线在AI处理器设计的初始就开始从整个芯片的系统级设计和芯片级别角度上思考SoC的设计思路,将经典芯片设计思想和带宽利用率优化结合在一起,注重真实的AI能力输出,既守住主效能又兼顾灵活效能的BPU思想。
以2020年最先商用量产的地平线征程二代芯片为例,搭载自主创新研发的高性能计算架构BPU2.0(Brain Processing Unit),可提供超过4TOPS的等效算力,典型功耗仅2瓦,且具有极高的算力利用率,典型算法模型在该芯片上处理器的利用率可以高于90%,能够高效灵活地实现多类AI任务处理,对多类目标进行实时检测和精准识别,可全面满足自动驾驶视觉感知、视觉建图定位、视觉ADAS等智能驾驶场景的需求,以及语音识别,眼球跟踪,手势识别等智能人机交互的功能需求,充分体现BPU架构强大的灵活性。
作为通用GPU 的代表供应商英伟达的自动驾驶系列芯片,通过添加神经网络单元,以实现对AI 处理越来越高效,但总体而言GPU 仍功耗较高。丰富的通用模块虽可实现对各种场景的适用性,但也带来了成本过高、功耗过高的问题。征程二代芯片具备极高的算力利用率,每TOPS AI能力输出可达同等算力GPU的10倍以上。与此同时,征程二代还可提供高精度且低延迟的感知输出,满足典型场景对语义分割、目标检测、目标识别的类别和数量的需求。
在最高性能模式下,如果自动驾驶控制器的芯片功耗级别较高,即便其自身性能强劲,但也会引发某些未可预知的隐患,如发热量成倍增加,耗电率成倍增加,这些结果尤其对于新能源车型来说也毫无疑问是颗“核弹”。因此,在前期自动驾驶芯片设计中需要充分考虑其功耗指标。
3)最小核心系统:
a)Core:内核通常是空间中心。一方面便于自动驾驶控制器和外围传感器、执行器通讯,同时也用外围来保护它。core强调运行态,通常出现的core-down,是指cpu计算上出现问题了,core强调的是自动驾驶控制器整体对外功能中的核心功能。
b)DMIPS:主要用于测整数计算能力。包含每秒钟能够执行的指令集数量,以及其这些指令集在实现我的测试程序的时候,每秒钟能够实现的工作数量,这个能力由cpu的架构,内存memory的访问速度等硬件特性来决定。它是一个测量CPU运行相应测试程序时表现出来的相对性能高低的一个单位(很多自动驾驶芯片评估场合,人们习惯用MIPS作为这个性能指标的单位)。
c)Memory:存储器管理单元的主要功能包括:虚拟地址到物理地址映射、存储器访问权限控制、高速缓存支持等;这里还包括一个支持最大的数据带宽,这个直接影响到数据传输的带宽。
d)DataFlash:DataFlash是美国ATMEL公司推出的大容量串行Flash存储器产品,采用Nor技术制造,可用于存储数据和程序代码。与并行Flash存储器相比,所需引脚少,体积小,易于扩展,与单片机或控制器连接简单,工作可靠,所以类似DataFlash的串行Flash控制器越来越多的用在自动驾驶控制器产品和测控系统评估中。
4)图像接口和图像处理能力
a)图像接口CSI:
CSI作为前端-配置逻辑接口,可以支持大多数通用的可用的CMOS摄像头接口,支持方便YCC,YUV,Bayer或者是RGB的数据格式输入,完全可控的8-bit或16-bit数据到32-bit的FIFO进行打包,32*32大小的FIFO存储接受到的的图像像素数据,该FIFO可以通过可编程的IO或者是DMA进行读取。
后端-提供了直接到eMMA的预处理PrP块接口(PrP和PP组成了MX27图形加速器eM MA,PrP和PP能够用来给视频做预处理和后期处理,例如,放大,缩小,颜色转换)。提供sensor的可屏蔽中断源,该中断源也是中断可控的,提供给外部sensor用的,可配置的主时钟频率,由统计数据产生的自动曝光(AE)和自动白平衡(AWB)控制。
b)视觉处理芯片ISP
ISP作为视觉处理芯片核心,其主要功能包括AE(自动曝光)、AF(自动对焦)、AWB(自动白平衡)、去除图像噪声、LSC(Lens Shading Correction)、BPC(Bad PixelCorrection),最后把Raw Data 保存起来,传给videocodec 或CV 等。通过ISP 可以得到更好的图像效果,因此在自动驾驶汽车上对ISP的要求很高,比如开始集成双通道甚至三通道的ISP。
一般来说ISP 是集成在AP 里面(对很多AP 芯片厂商来说,这是差异化竞争的关键部分),但是随着需求的变化也出现了独立的ISP,主要原因是可以更灵活的配置,同时弥补及配合AP 芯片内ISP 功能的不足。
c)图像绘制芯片GPU:
GPU是基于大的吞吐量设计,用来处理大规模的并行计算。GPU的控制单元可以把多个的访问合并成少的访问。GPU将更多的晶体管用于执行单元,而非像CPU那样用作复杂的数据cache和指令控制。由于GPU具有超强的浮点计算能力,可用于在智能汽车前端的图像或视频处理领域的应用,也越来越多地应用在中央控制器高性能计算的主流设计中。
5)丰富的传感器相关接口包括以太网和CAN
ETH和CAN:中央控制器芯片设计中需要充分考虑其连接接口是否支持以太网和CANFD等高级数据连接传输方式,这是接收并有效处理数据的前提。
需要支持丰富的接口,通过对比分析,自动驾驶系统传感器数量很多但是种类无外乎摄像头、激光雷达、毫米波雷达、超声波雷达、组合导航、IMU、V2X模块等。
自动驾驶系统对于摄像头可供选择的不是很多,接口类型有MIPI SI-2、LVDS、GMSL、FPDLink等;激光雷达都是Ethernet接口,目前大多是普通Ethernet;毫米波雷达都是CAN总线传输;超声波雷达LIN总线就够了;组合导航和惯导常见接口为RS232串口;V2X模块采用Ethernet接口传输。
需要支持PCIE接口:
一般的应用场景中,集成一个主芯片就能够满足计算资源的需求,但是自动驾驶对算力有着更高的要求,有时候于安全的考虑,也需要同时集成多个主芯片,其结构一般如下图所示:
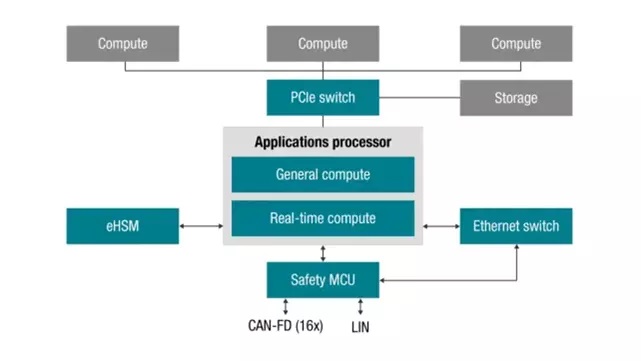
多个芯片在需要在PCIe Switch的连接下共同组成一个计算单元,如果以后发展成可动态拓展的形式(类似于刀片机),该结构依然适用,以下是采用两个Xavier芯片组成的一个高性能计算单元的示意图: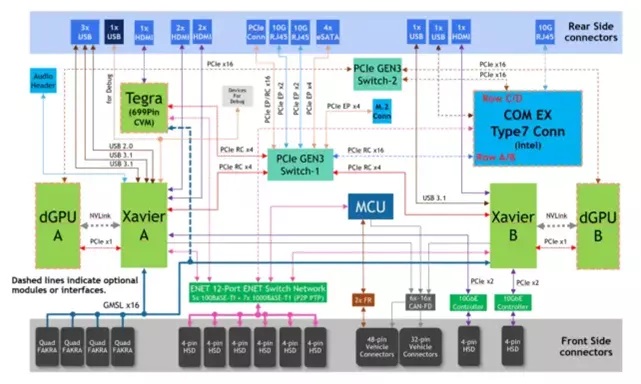
6)主芯片需要满足车规及功能安全的需求
人工智能时代车规级AI芯片成为皇冠上的明珠,竞争壁垒高。终端侧的AI芯片,车规级AI芯片是皇冠上的明珠。由于车规级标准极难认证,车规级人工智能芯片代表了芯片行业中的最高标准,与消费级和工业级芯片相比,车规级AI芯片在安全性、可靠性和稳定性上都有最高的要求。必须要达到,车载环境温度在-40℃到125℃区间,故障率为0。
因为对安全性、可靠性的要求高,所以芯片从设计到车上测试验证、真正实现量产一般需要至少4~5年。由于车规级芯片开发周期长、设计难度大,属于长跑创新,一旦建立起领先优势,龙头厂商将具有较高的竞争壁垒,人工智能时代车规级AI芯片成为皇冠上的明珠,领先厂商竞争壁垒较高。
现在自动驾驶的芯片不仅仅需要过AECQ100的车规级要求,而且要求增加功能安全的认证要求。
功能安全目标是整个自动驾驶中央控制器的核心设计需求,由于其影响对整个自动驾驶功能设计中的单点失效分析结果,因此,在前期硬件设计中就需要充分考虑其是否能够完全满足系统对于硬件的功能安全设计需求。
功能安全在芯片上的设计原则是要尽可能多的找出芯片上的失效场景并纠正。失效又分为系统和随机两种,前者依靠设计时的流程规范来保证,后者依赖于芯片设计上采取的种种失效探测机制来保证。我们在这主要谈后者。简单来说,芯片的失效率,是基于单个晶体管在某个工艺节点的失效概率,推导出片上逻辑或者内存的失效概率。面积越大,晶体管越多,相应的失效率越大。
ISO26262把安全等级做了划分,常见的有ASIL-B和ASIL-D级。ASIL-B要求芯片能够覆盖90%的单点失效场景,而ASIL-D则是99%。这其实是个非常高的要求。一个晶体管的失效概率虽低,可是通常一个复杂芯片是上亿个晶体管组成的,如果不采取任何措施,那任何一点的错误都可能造成功能失效,失效率很高,这对于芯片设计来说需要增加非常多的冗余措施和开发成本,不是一蹴而就的,目前过了产品的芯片的ISO26262的功能认证的自动驾驶芯片不多,特斯拉就没有过,当然它是特独立的芯片厂家,但是我们在选择自动驾驶平台的时候需要考虑这个因素。
自动控制需要负责可靠性和车辆控制,也就是功能安全和冗余监控作用,不要求很高的算力,但是可靠性必须要有保障,ISO26262等级要求达到ASIL-D,目前用的较多的就是Infineon的TC297或者TC397,为了达到功能安全,同地平线总监沟通,目前它们这部分控制的MCU也是给到英飞凌芯片做控制,地平线那边输出对应的图像或雷达处理信息,给到英飞凌的MCU去做最终的控制算法。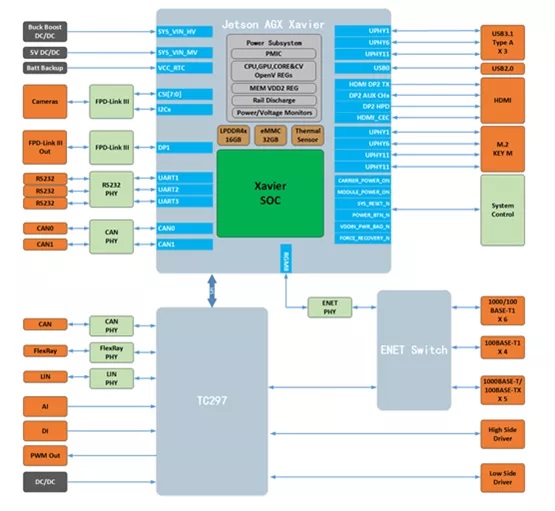
优控智行的域控制器型号为EAXVA03,据说是第三代产品已经小批量装车。其内置NVIDIA Xavier和Infineon TC297T。按照设计部署,Xavier用于环境感知、图像融合、路径规划等,TC297用于安全监控、冗余控制、网关通讯及整车控制。
自动驾驶计算平台对比及选择平台考虑因素
自动驾驶计算平台比较
前面提到L2级别需要2个TOPS的算力,L3需要24个TOPS的算力,L4为320TOPS,L5为4000+TOPS。
这里可以看到目前主流的自动驾驶计算平台的算力普遍都在200+TOPS,当然特斯拉是没有达到200TOPS,它是没有激光雷达,这部分所需要的数据处理能力要求降低很多。
这里可以看到很有意思的事情,单个xavier的算力只有30TPOS,但是通过PCIE等连接方式,这样计算平台的算力明显提升,计算平台英伟达的DRIVE PX Pegasus的算力达到320TPOS,比特斯拉HW3.0的算力还大。
自动驾驶芯片平台终极考虑因素
先直接给出相关结论,针对这些结论进行相关内容的阐述;
1)较强的神经网络算法能力,智能汽车主控芯片核心是神经网络单元的设计;
2)自动驾驶汽车计算单元设计需要考虑算力、功耗体积等问题,同时做到芯片设计、算法最优化,有效算力最大;
3)有能力提供“软硬一体”平台级解决方案,需要建立足够开放生态使OEM厂商和Tier1可以进行二次开发,同时为客户提供感知、制图、行驶策略等解决方案。
4)政治相关因素,哪些芯片合作不受美国等西方政府限制等等;
较强的神经网络算法能力:
AI算法能力在对自动驾驶和汽车智能化重要应用场景的关键算法发展趋势进行提前预判,前瞻性地将其计算特点融入到计算架构的设计当中。AI算法是车规AI芯片的灵魂,也对芯片设计带来了更大的挑战,神经网络算法的迭代速度远超硬件的改进速度,一旦设计时考虑不当,将会造成芯片设计结束时算法全面落后的情况,需要针对ADAS应用进行极致优化。
地平线创始人余凯博士是全球最顶尖的AI专家,地平线拥有全球领先的算法团队,前瞻性的对重要应用场景中的关键算法发展趋势进行预判,提前将其计算特点融入到计算架构的设计当中,使得AI处理器经过一两年的研发,在推出的时候,仍然能够很好地适应时下最新的主流算法。
因此和其他典型的AI处理器相比,地平线的AI处理器,随着算法的演进趋势,始终能够保持相当高的有效利用率,从而真正意义上受益于算法创新带来的优势。全球领先的AI算法能力是公司区别于AMD、瑞萨、高通等传统芯片制造商的最大优势。公司掌握了算法和计算架构,再利用自己开发的编译器对算法和芯片同时进行极致优化,释放出所有的潜能。
除了AI的算法,还需要对于一些控制的算法有优化,否则硬件能力再强,没有软件优化的能力,这些硬件配置只能更高。
域控制器ECU资源分配及优化
自动驾驶控制器的整个ECU资源需要在其具体的算法控制中得到算力分配,其中关键的AD处理过程包括如下主要的几个部分。道路运动目标检测、道路结构检测(基于前视摄像头)、目标形态检测、预测分析、道路结构检测(基于侧视摄像头)、道路运动目标检测(基于侧视摄像头)。各部分参数主要包括了对CPU运行资源、算力、运行带宽、运行时间等,如下表表示了一种典型的各个算法对于算力运行占用的资源统计分析,其中两个不同的芯片分别暂用不同计算需求。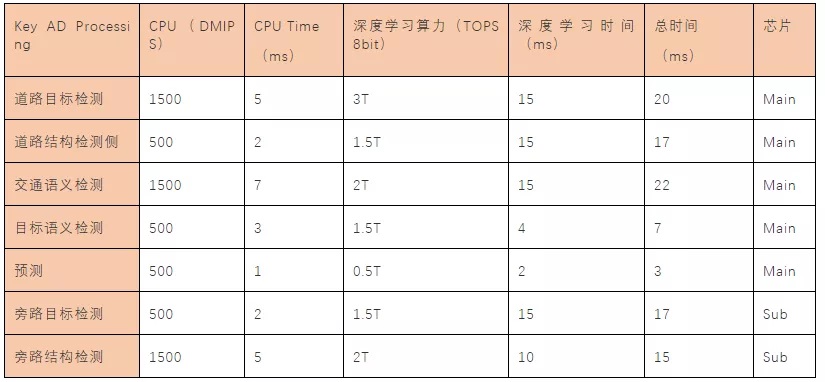
由于芯片算力的有效利用率影响着整个算法效率,因此对算力的计算和分析是提前。
如上软件模块算法的算力效率牵涉到MAC计算效率问题。如果相应的自动驾驶模块算法或者说CNN卷积需要的算力是1TOPS,而运算平台的算力是4TOPS,那么利用效率只有25%,运算单元大部分时候都在等待数据传送,特别是批量待处理的尺寸较小时候,存储带宽不足会严重限制性能。但如果超出平台的运算能力,延迟会大幅度增加,存储瓶颈一样很要命。效率在90-95%情况下,存储瓶颈影响最小,但这并不意味着不影响了,影响依然存在。然而平台不会只运算一种算法,运算利用效率很难稳定在90-95%。
因此,是否能匹配比较高效的算法也是一个选择芯片平台的重要因素。